
Реализация Bloom Filter на go https://github.com/GermanGorelkin/bloom-filter
В условиях экспоненциального роста данных традиционные структуры часто упираются в лимиты памяти.
Фильтр Блума - это вероятностная структура данных, которая позволяет мгновенно проверить: “Возможно, элемент есть в множестве” или “Его точно там нет”.
Применение фильтра Блума предполагает осознанный компромисс: в обмен на исключительную экономию пространства и константное время выполнения операций система допускает небольшую, но контролируемую вероятность ложноположительных срабатываний.
Этот инструмент стал gatekeeper в современной архитектуре, радикально сокращая количество дорогих I/O-операций.
Механика “Битового сита”
Фильтр Блума базируется на двух компонентах:
- Битовый массив размера
m. - Набор из
kнезависимых хеш-функций.
Сами элементы в структуре не хранятся; это обеспечивает компактность и приватность - восстановить исходные данные по битам невозможно.
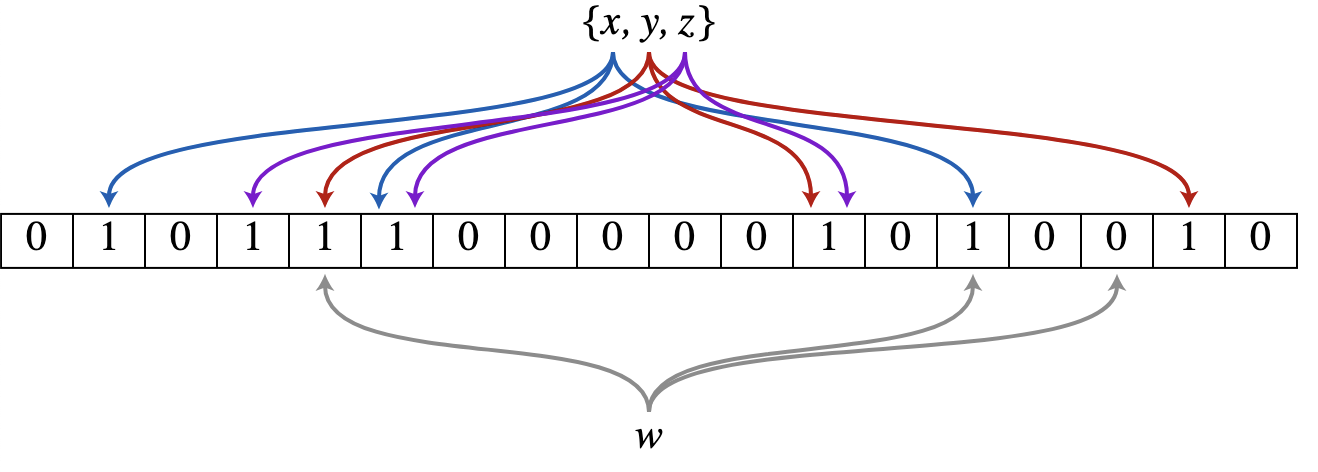
Алгоритм операций
- Добавление: Элемент прогоняется через
kхеш-функций. Каждая дает индекс в массиве, и бит по этому адресу устанавливается в1. - Проверка: Элемент снова хешируется.
- Если хотя бы один бит равен
0- элемента точно нет в множестве (100% гарантия). - Если все биты равны
1- элемент вероятно есть в множестве.
- Если хотя бы один бит равен
// BitSet - стандартная реализация BitSet на основе []uint64.
// Использует uint64 для эффективных битовых операций.
type BitSet struct {
bits []uint64
size uint64
}
// Filter определяет интерфейс для всех типов фильтров.
type Filter interface {
// Add добавляет элемент в фильтр
Add(data []byte) error
// Test проверяет, возможно ли элемент находится в фильтре
Test(data []byte) bool
// Reset очищает фильтр (все элементы удаляются)
Reset()
// Stats возвращает статистику фильтра
Stats() Stats
}
// BloomFilter - классическая реализация Bloom фильтра.
// Ключевые свойства:
// - Нет false negatives: если элемент был добавлен, Test всегда вернет true
// - Возможны false positives: Test может вернуть true для элементов, которые не были добавлены
// - Компактность: использует значительно меньше памяти чем хранение всех элементов
// - Производительность: O(k) для Add и Test, где k - количество хэш-функций
type BloomFilter struct {
// Компоненты фильтра (через интерфейсы для расширяемости)
bitset BitSet
hasher Hasher
// Параметры фильтра
m uint64 // размер битового массива в битах
k uint // количество хэш-функций
// Счетчики
count uint64 // количество добавленных элементов (atomic)
}
Сложность операций
Эффективность фильтра Блума проявляется в его способности выполнять операции за фиксированное время, не зависящее от количества уже вставленных элементов.
| Параметр | Сложность | Комментарий |
|---|---|---|
| Добавление (Add) | O(k) |
Зависит только от количества хеш-функций, не зависит от размера данных n. |
| Поиск (Test) | O(k) |
Константное время, определяемое вычислительной мощностью для хеширования. |
| Память (Space) | O(m) |
Пространство фиксировано и не растет при добавлении новых элементов (хотя точность падает). |
Для вероятности ошибки в 1% требуется всего около 9.6 бит на элемент, независимо от его реального размера (будь то ID или текст на 10 КБ).
Математика точности и оптимизация
Точность фильтра - это баланс между m (память), n (количество элементов) и k (хеши).
Вероятность ложноположительного срабатывания
- Вероятность, что конкретный бит останется
0после вставки всехnэлементов:
P(0) = (1 - 1/m)^{k n} ≈ e^{-k n / m}
- Вероятность того, что бит равен
1:1 - e^{-k n / m}. - Следовательно, вероятность ложноположительного срабатывания:
P(fp) = (1 - e^{-k n / m})^k
// EstimateFalsePositiveRate оценивает вероятность false positive для
// заданных параметров фильтра.
//
// Формула: p = (1 - e^(-kn/m))^k
//
// Параметры:
// - m: размер битового массива в битах
// - k: количество хэш-функций
// - n: количество добавленных элементов
//
// Возвращает оценку вероятности false positive.
func EstimateFalsePositiveRate(m uint64, k uint, n uint64) float64 {
if m == 0 || k == 0 {
return 1.0
}
// p = (1 - e^(-kn/m))^k
exponent := -float64(k) * float64(n) / float64(m)
return math.Pow(1-math.Exp(exponent), float64(k))
}
Оптимальное число хеш‑функций k
k_opt = (m / n) * ln 2 ≈ 0.693 * (m / n)
При этом Bits-per-item (m/n) для заданной целевой вероятности p:
m/n = - (ln p) / (ln 2)^2 ≈ 1.44 * log2(1/p)
Для p = 1% это даёт ≈ 9.6 бита на элемент.
// OptimalK вычисляет оптимальное количество хэш-функций (k) на основе
// ожидаемого количества элементов (n) и размера битового массива (m).
//
// Формула: k = (m/n) * ln(2)
//
// Параметры:
// - n: ожидаемое количество элементов
// - m: размер битового массива в битах
//
// Возвращает оптимальное количество хэш-функций.
func OptimalK(n, m uint64) uint {
if n == 0 {
return 1
}
k := (float64(m) / float64(n)) * math.Ln2
result := uint(math.Ceil(k))
if result == 0 {
return 1
}
return result
}
Оптимальный размер битового массива
// OptimalM вычисляет оптимальный размер битового массива (m) на основе
// ожидаемого количества элементов (n) и желаемой вероятности ложных срабатываний (p).
//
// Формула: m = -n * ln(p) / (ln(2)^2)
//
// Параметры:
// - n: ожидаемое количество элементов
// - p: желаемая вероятность false positive (должна быть между 0 и 1)
//
// Возвращает размер битового массива в битах.
func OptimalM(n uint64, p float64) uint64 {
m := -float64(n) * math.Log(p) / (math.Ln2 * math.Ln2)
return uint64(math.Ceil(m))
}
Максимальное количество элементов для достижения заданной вероятности false positive
// EstimateCapacity оценивает максимальное количество элементов,
// которое можно добавить в фильтр для достижения заданной вероятности false positive.
//
// Обратная формула от OptimalM:
// n = -m * (ln(2)^2) / ln(p)
//
// Параметры:
// - m: размер битового массива в битах
// - k: количество хэш-функций
// - p: желаемая вероятность false positive
//
// Возвращает оценку максимальной емкости.
func EstimateCapacity(m uint64, p float64) uint64 {
if p <= 0 || p >= 1 {
return 0
}
// n = -m * (ln(2)^2) / ln(p)
n := -float64(m) * math.Ln2 * math.Ln2 / math.Log(p)
return uint64(math.Ceil(n))
}
Динамика изменения точности
С ростом числа вставленных элементов n массив заполняется единицами, и вероятность ложноположительных срабатываний увеличивается.
Когда половина бит массива установлена в 1, фильтр достигает своей оптимальной информационной энтропии, но дальнейшее заполнение ведет к резкой деградации точности.
Если все биты будут установлены в 1, фильтр станет бесполезным, возвращая “да” на любой запрос.
Хеширование и оптимизация
Выбор хеш-функций критически важен для производительности; функции должны быть быстрыми, независимыми и обеспечивать равномерное распределение бит по всему массиву.
Использование некриптографических функций
В большинстве высоконагруженных систем использование криптографических хеш-функций (таких как SHA-256 или MD5) считается нецелесообразным из-за их высокой ресурсоемкости.
Вместо них применяются современные некриптографические алгоритмы:
- MurmurHash3: Популярный выбор для фильтров Блума благодаря отличному распределению и высокой скорости; широко используется в библиотеках Google Guava и Apache Cassandra.
- xxHash: Один из самых быстрых алгоритмов хеширования, оптимизированный для современных процессоров, использующий инструкции SIMD; применяется в RocksDB.
- FNV (Fowler-Noll-Vo): Эффективен для коротких строк, прост в реализации, но может уступать MurmurHash в качестве распределения на больших наборах данных.
Оптимизация Кирша-Митценмахера (Double Hashing)
Для снижения вычислительной нагрузки при использовании большого числа k хеш-функций применяется метод двойного хеширования.
Исследования Кирша и Митценмахера подтвердили, что можно имитировать k независимых функций, используя результаты всего двух базовых хешей h_1(x) и h_2(x):
g_i(x) = (h1(x) + i * h2(x)) mod m, i = 0..k-1
// Hash генерирует k хэш-значений используя MurmurHash3.
// Оптимизация: генерирует 2 базовых хэша (128 бит) и комбинирует их для получения k хэшей.
// Формула: hash_i = h1 + i*h2
func (m *MurmurHasher) Hash(data []byte, k uint) []uint64 {
// Используем 128-битный MurmurHash3 для получения двух 64-битных хэшей
h1, h2 := murmur3.Sum128(data)
hashes := make([]uint64, k)
for i := uint(0); i < k; i++ {
// Комбинируем два базовых хэша для получения i-го хэша
hashes[i] = h1 + uint64(i)*h2
}
return hashes
}
Экономит CPU и в большинстве практических сценариев даёт статистически эквивалентные результаты независимым хешам.
Где это применяется в реальном мире?
Интеграция фильтров Блума в систему позволяет решать широкий спектр задач оптимизации, от снижения нагрузки на дисковую подсистему до ускорения сетевых протоколов.
Предотвращение лишних дисковых операций в LSM-деревьях
В базах данных с архитектурой Log-Structured Merge-tree (LSM), таких как Apache Cassandra, RocksDB, LevelDB и HBase, данные хранятся в неизменяемых файлах на диске (SSTables).
Чтение ключа требует проверки нескольких файлов, что может привести к множественным операциям поиска на диске.
- Механизм: Для каждой SSTable создается свой фильтр Блума, который загружается в оперативную память.
- Результат: Прежде чем выполнять чтение с диска, система опрашивает фильтр; если ключ “точно отсутствует”, чтение этого SSTable пропускается; это сокращает объем дискового I/O на порядок, особенно для запросов к несуществующим данным.
Фильтрация “одноразовых” запросов в CDN (Akamai)
Сети доставки контента сталкиваются с проблемой “one-hit wonders” - объектов, которые запрашиваются пользователями ровно один раз и больше никогда не востребуются.
Кэширование таких объектов неэффективно расходует дисковое пространство.
- Механизм: Akamai использует фильтры Блума для отслеживания всех входящих запросов к ресурсам.
- Логика: Объект помещается в кэш только в том случае, если фильтр Блума показывает, что этот ресурс уже запрашивался ранее (второй запрос); это позволяет отсеять до 75% бесполезного контента, увеличивая коэффициент попадания в кэш (hit rate) для действительно популярных данных.
Оптимизация распределенных соединений (Bloom Join)
В аналитических системах обработки больших данных (Big Data), таких как Apache Spark, операция соединения (join) двух таблиц требует перемещения огромных объемов данных между узлами сети (shuffle).
- Механизм: Если одна из таблиц мала, на ее стороне строится фильтр Блума по ключам соединения; этот компактный фильтр рассылается на все узлы, хранящие разделы большой таблицы.
- Результат: Узлы с большой таблицей предварительно фильтруют свои строки, отбрасывая те, которые гарантированно не найдут соответствия в малой таблице. В результате по сети передается лишь малая часть данных, что радикально ускоряет выполнение запроса.
Веб-браузеры и системы безопасности
Браузеры, такие как Google Chrome, используют фильтры Блума для реализации списков вредоносных URL-адресов (Safe Browsing).
- Механизм: Вместо того чтобы хранить миллионы строк URL или отправлять каждый запрос на сервер Google, браузер хранит локальный фильтр Блума.
- Процесс: При попытке перехода на сайт браузер сначала проверяет его через фильтр; если фильтр дает положительный ответ, выполняется полноценный сетевой запрос для подтверждения угрозы; это защищает конфиденциальность пользователя и снижает нагрузку на API.
Bitcoin и Ethereum
В блокчейн-сетях фильтры Блума решают проблему ограниченных ресурсов на клиентских устройствах.
В протоколе Bitcoin (BIP 37) фильтры Блума используются “легкими” узлами (SPV-клиентами) для запроса только тех транзакций, которые относятся к их кошелькам.
Клиент передает фильтр полному узлу, который затем пересылает только совпадающие транзакции.
Однако из-за проблем с конфиденциальностью (возможность деанонимизации адресов через анализ фильтра) этот подход был признан устаревшим и заменяется клиентской фильтрацией (BIP 157/158).
Ethereum использует фильтры Блума для быстрого поиска событий (логов), генерируемых смарт-контрактами.
Каждый заголовок блока содержит 2048-битный фильтр Блума, агрегирующий информацию обо всех логах в блоке.
Это позволяет клиентам мгновенно отсеивать блоки, в которых нет интересующих их событий, не скачивая всё тело блока.
Сетевые протоколы и маршрутизация
Bloom-фильтры применяются в сетевых и распределённых системах для сокращения объёма информации о маршрутах или ресурсах.
Например, в пиринговых (P2P) сетях и системах обмена контентом фильтр может компактно представлять список хранимых ключей или фрагментов, позволяя быстро решить, отправлять ли запрос дальше.
Cache Digest в прокси Squid: сервера периодически обмениваются BF своих кешей, чтобы каждый узел знал, какие объекты есть у соседей.
При этом “проверки” по BF быстры и практически не создают задержки, зато позволяют пропускать пустые обращения и улучшать сетевую пропускную способность.
В исследованиях сети также рассматриваются методы маршрутизации с Bloom-фильтрами: например, BF используются для компактного описания всех адресов или префиксов, которыми управляет узел.
Это позволяет при передаче пакета быстро исключить ссылки, не ведущие к цели, и значительно снизить нагрузку на таблицы маршрутизации.
Вариации и альтернативные вероятностные структуры
Классический фильтр Блума имеет ряд ограничений, таких как невозможность удаления элементов и фиксированный размер.
Для решения этих проблем были разработаны специализированные варианты.
Counting Bloom Filter (Счетный фильтр Блума)
Для поддержки удаления элементов битовый массив заменяется массивом счетчиков (обычно 4 бита на ячейку).
- Механизм: При вставке счетчики инкрементируются, при удалении - декрементируются; если счетчик больше нуля, значит, позиция занята.
- Недостаток: Требует в 4 раза больше памяти по сравнению со стандартным фильтром.
Scalable Bloom Filter (Масштабируемый фильтр Блума)
Позволяет динамически расширять фильтр при добавлении новых элементов без необходимости перестраивать всю структуру.
- Механизм: Представляет собой последовательность обычных фильтров Блума; когда первый фильтр заполняется до порога, создается второй, с меньшей вероятностью ошибки. Проверка выполняется во всех фильтрах цепочки.
Cuckoo Filter (Кукушкин фильтр)
Основан на алгоритме кукушкиного хеширования и хранит короткие отпечатки (fingerprints) элементов.
- Преимущества: Поддерживает удаление “из коробки”, обеспечивает более высокую скорость поиска (требуется всего два обращения к памяти) и часто более компактен при низких целевых вероятностях ошибок (ниже 3%).
- Сложность: Вставка может завершиться неудачей, если хеш-таблица переполнена и не удается найти место для перемещения элементов.
Ribbon Filter
Современная структура, внедренная в RocksDB, использующая методы линейной алгебры для построения компактного представления множества.
- Эффективность: Позволяет экономить до 30% памяти по сравнению с традиционными фильтрами Блума при той же точности; идеально подходит для статических наборов данных, таких как закрытые SSTables.
Высокопроизводительная реализация
- Шардирование массива для уменьшения конкуренции (striped/partitioned Bloom).
- Аппаратные ускорители: GPU для пакетного хеширования, NIC‑offload в сетевых сценариях.
- Ribbon и другие компактные фильтры для статических наборов данных.
Итоги и рекомендации
- Целевая точность:
1%- стандарт,0.1%- для критичных к диску систем. - Память: Рассчитывайте
mзаранее, исходя из ожидаемогоn. - Удаление: Если оно критично - сразу смотрите в сторону Cuckoo Filter.
- Используйте double hashing для снижения затрат на CPU.
Комментарии в Telegram-группе!