
Кластеры редко бывают статичными: узлы добавляются для масштабирования и выбывают из-за сбоев. В таких условиях обычное распределение нагрузки становится неэффективным. На помощь приходит Consistent Hashing - алгоритм, который гарантирует минимальное перемещение ключей при любых изменениях в составе системы.
Недостатки детерминированного хеширования по модулю
Прежде чем разбирать консистентное хеширование, вспомним базу; обычно в распределенных системах ключи раскидывают по серверам через простую формулу: index = hash(key) % n, где n - число серверов; это просто и даёт хорошее распределение при статическом составе.
Когда количество серверов n меняется хотя бы на единицу, знаменатель в формуле остатка меняется, что приводит к радикальному изменению отображения практически всех ключей в системе.
Статистически, при добавлении одного нового узла в кластер из n серверов, около n/(n+1) всех существующих ключей изменят своего владельца.
В контексте распределенного кеша это вызывает массовое недействительность данных (cache miss), что провоцирует “кеш-шторм”: лавинообразный поток запросов обрушивается на нижележащую базу данных, часто приводя к ее отказу и каскадному падению всей инфраструктуры.
Идея кольца (hash ring)
Решение проблемы масштабного перераспределения данных было предложено в 1997 году Дэвидом Каргером и его коллегами из MIT в статье Consistent Hashing and Random Trees.
Основная идея заключалась в том, чтобы отделить хеш-пространство ключей от текущего состава серверного кластера.
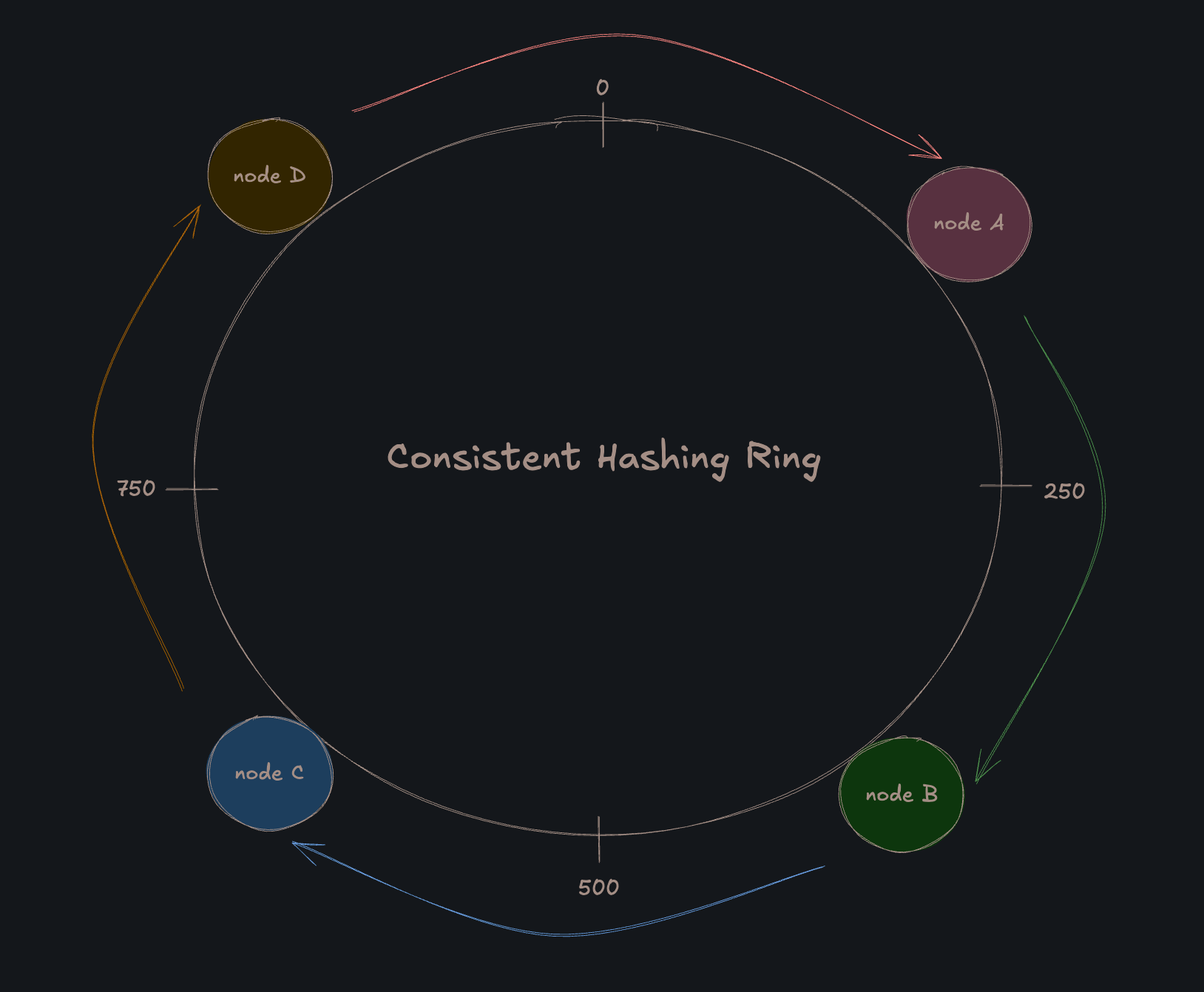
В консистентном хешировании диапазон возможных выходных значений хеш-функции рассматривается как фиксированное круговое пространство, называемое “хеш-кольцом”.
Предположим, используется хеш-функция, генерирующая 32-битные целые числа; в этом случае хеш-пространство представляет собой диапазон от 0 до 2^32-1.
Мы можем визуализировать этот диапазон как окружность, где значение 2^32 совпадает с нулем.
На это кольцо отображаются два типа объектов:
- Узлы (серверы): Идентификаторы серверов (IP-адрес, имя хоста или UUID) хешируются с использованием той же функции, что и данные, и занимают определенные точки на кольце.
- Ключи (объекты данных): Каждый ключ также хешируется и получает свою координату на окружности.
Алгоритм сопоставления и принцип локальности
Чтобы определить, на каком сервере должен храниться конкретный ключ, система находит позицию ключа на кольце и начинает движение по часовой стрелке (или против, в зависимости от реализации, но конвенционально - по часовой) до первого встретившегося сервера; этот сервер объявляется ответственным за хранение данного ключа.
Таким образом, каждый узел становится ответственным за сегмент кольца, расположенный между ним и его предшественником.
Этот геометрический подход обеспечивает ключевое свойство: при добавлении или удалении узла изменения затрагивают только его непосредственных соседей на кольце.
Когда в систему добавляется новый сервер S_new, он занимает позицию между серверами S_prev и S_next.
Все ключи, которые ранее отображались на сегмент, теперь занятый S_new, передаются от S_next новому серверу; остальные серверы кластера продолжают обслуживать свои неизменные диапазоны, и ни один ключ, не попадающий в новый сегмент, не требует перемещения.
Правило простое: ключ “идёт” по кругу по часовой стрелке до первого встретившегося сервера - этот сервер и хранит ключ.
Тогда при добавлении или удалении одного сервера изменяются только ключи, попадающие в соседний сегмент кольца - т.е. перемещается небольшой процент данных, а не почти всё.
Оптимизация распределения
Первоначальная модель консистентного хеширования обладала существенным недостатком: случайное размещение серверов на кольце часто приводило к формированию неравномерных сегментов ответственности.
Один сервер мог случайно оказаться “владельцем” огромного участка кольца, в то время как другие обслуживали лишь крошечные фрагменты; это приводило к появлению “горячих точек” (hotspots), где нагрузка на отдельные узлы превышала их возможности, даже если суммарная мощность кластера была достаточной.
Механизм репликации идентификаторов (VNodes)
Для исправления этого дисбаланса была введена концепция виртуальных узлов (Virtual Nodes или VNodes).
Идея заключается в том, что каждый физический сервер представляется на хеш-кольце не одной, а множеством точек.
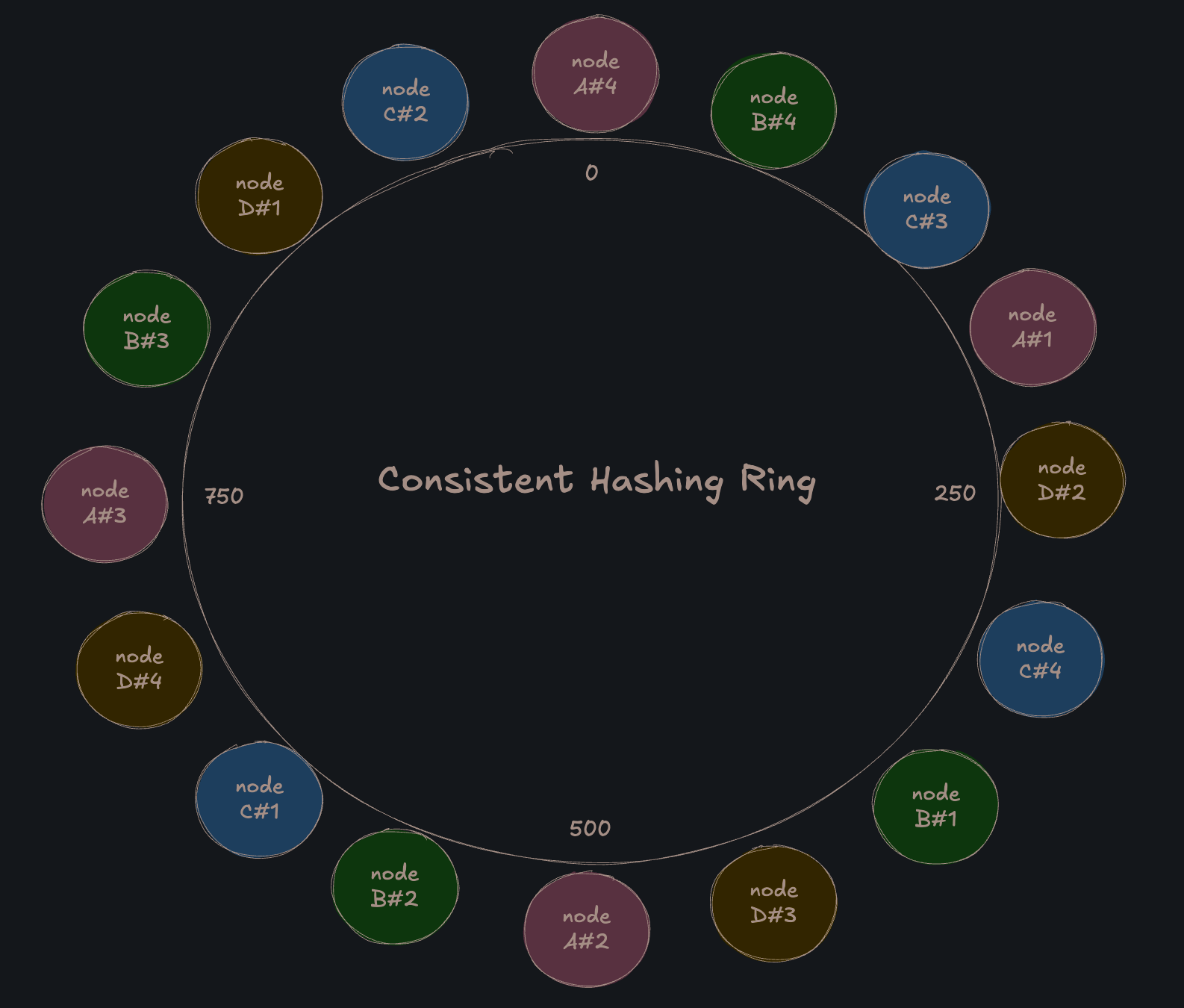
Процесс создания виртуальных узлов включает генерацию нескольких уникальных имен для каждого сервера (например, “Node-A#1”, “Node-A#2”,… “Node-A#200”) и их хеширование.
Это приводит к тому, что физический сервер оказывается распределенным по всему кольцу в виде множества небольших фрагментов ответственности.
Структуры данных и поиск
На практике реализация консистентного хеширования требует эффективных алгоритмов поиска точки на кольце.
Поскольку в крупных системах количество виртуальных узлов может исчисляться десятками тысяч, линейный перебор всех позиций недопустим.
Отсортированные массивы и бинарный поиск
Самый распространенный способ реализации - использование отсортированного списка или массива хеш-значений всех виртуальных узлов в системе.
- При инициализации все хеши виртуальных узлов сортируются в порядке возрастания.
- Для каждого запроса вычисляется хеш ключа
h_key. - Используется модифицированный бинарный поиск для нахождения первого элемента в массиве, значение которого
>= h_key. - Если
h_keyбольше самого большого значения в массиве, выбирается первый элемент (индекс 0), что имитирует круговую структуру кольца.
Сложность поиска в такой структуре составляет O(log M), где M - общее количество виртуальных узлов.
Выбор хеш-функции
Для консистентного хеширования критически важны два свойства функции: равномерность распределения и вычислительная эффективность.
- MD5 и SHA-1: Традиционно использовались в ранних системах благодаря их способности генерировать лавинообразный эффект, когда минимальное изменение входных данных радикально меняет выход; однако эти функции являются криптографическими и создают значительную нагрузку на CPU.
- MurmurHash3: Стал фактическим стандартом в современных распределенных базах данных; это некриптографическая функция, оптимизированная для скорости работы и обеспечивающая отличное распределение ключей; она работает в 3-5 раз быстрее MD5, что критично при обработке миллионов запросов в секунду.
Проблемы
Несмотря на элегантность, консистентное хеширование в реальной эксплуатации сталкивается с рядом вызовов, которые требуют дополнительных архитектурных мер.
Каскадные отказы и эффект домино
В системе без виртуальных узлов отказ одного сервера приводит к тому, что вся его нагрузка мгновенно переходит к одному соседу по часовой стрелке.
Если соседний сервер уже работал на 80% мощности, внезапный приток новых запросов вызовет его перегрузку и последующий отказ; это создает цепную реакцию, которая может уничтожить весь кластер за минуты.
Виртуальные узлы служат “предохранителем” в этой ситуации.
Поскольку VNodes упавшего сервера распределены по всему кольцу, нагрузка переходит к множеству различных физических серверов по чуть-чуть. Это распределение “рассеивает” удар, позволяя кластеру поглотить всплеск трафика без критических последствий.
Проблема “Горячих ключей” (Hot Key Crisis)
Ни один алгоритм хеширования не может защитить от ситуации, когда один конкретный ключ становится аномально популярным.
В случае Discord или Twitter это может быть аккаунт знаменитости с миллионами подписчиков. Весь трафик к этому ключу будет направлен на один сервер (и его реплики).
Для борьбы с этим используются стратегии, выходящие за рамки чистого хеширования:
- Динамическая репликация: Обнаружение “горячих” ключей и их временное тиражирование на большее количество узлов кольца.
- Двухуровневое кеширование: Использование локального кеша на стороне клиента или прокси-сервера, чтобы снизить количество запросов к основному хранилищу.
Атомарность и консистентность при переселении данных
Хотя консистентное хеширование минимизирует количество перемещаемых ключей, сам процесс миграции данных между узлами остаётся нетривиальной задачей.
Главная проблема здесь - сохранить атомарность и консистентность доступа, чтобы во время переселения данные не “пропали” и не оказались у двух владельцев одновременно.
При добавлении нового узла часть диапазона кольца меняет владельца.
В этот момент возможны несколько опасных состояний:
- клиент читает данные, которые уже переехали, но маршрутизация ещё указывает на старый узел;
- запись приходит на старый узел, хотя формально владельцем стал новый;
- часть данных уже скопирована, а часть - ещё нет.
Если ничего с этим не делать, система получит либо потерю данных, либо расхождение версий, либо временную недоступность ключей.
Почти все промышленные системы следуют одному правилу: Сначала данные дублируются, и только потом меняется логический владелец.
Это означает, что в течение некоторого времени данные могут существовать на двух узлах, но система знает, какой из них является “источником истины”.
Streaming / Bootstrap (фоновая миграция)
При добавлении нового узла он не начинает обслуживать запросы сразу.
Процесс обычно выглядит так:
- Новый узел определяется как будущий владелец диапазона.
- Старые узлы начинают стриминг данных (поблочную передачу ключей) новому.
- До завершения стриминга старый узел продолжает обслуживать запросы.
- После завершения копирования маршрутизация переключается на новый узел.
Такой подход используют, например, Cassandra и Dynamo-подобные системы.
Dual Writes / Read Repair (временные дублёры)
На время миграции система может:
- принимать записи на оба узла (старый и новый);
- читать с обоих узлов, сверяя версии данных.
Это увеличивает нагрузку, но обеспечивает, что ни одна запись не потеряется; после завершения миграции лишняя копия удаляется или становится репликой.
Hinted Handoff
Механизм hinted handoff используется, когда целевой узел временно недоступен:
- запись принимается другим узлом;
- вместе с данными сохраняется “подсказка” (hint), кому они предназначались;
- когда целевой узел возвращается в строй, данные ему “доставляются”.
Во время ребалансировки hinted handoff помогает пережить ситуации, когда новый узел ещё не полностью готов принимать весь поток записей.
Версионирование и согласование
Чтобы корректно разрешать конфликты, системы применяют:
- версии данных (timestamps, vector clocks);
- кворумные операции (например, запись считается успешной, если её подтвердили
WизRреплик).
Даже если клиент попал “не туда” во время миграции, система сможет либо:
- перенаправить запрос,
- либо восстановить актуальную версию при следующем чтении (read repair).
Другие варианты
Консистентное хеширование - не единственный вариант; в зависимости от специфики задачи могут применяться альтернативные подходы.
| Алгоритм | Основная идея | Сильные стороны | Слабые стороны |
|---|---|---|---|
| Ring Hashing | Классическое кольцо с VNodes | Стандарт индустрии, гибкость | Сложность управления состоянием кольца |
| Rendezvous (HRW) | Вычисление веса для каждой пары (ключ, узел) | Нет необходимости в кольце, идеальный баланс | Вычислительная сложность O(N) при поиске |
| Jump Hash | Вероятностный алгоритм без хранения данных | Экстремальная скорость, 0 памяти | Не поддерживает удаление узлов из середины списка |
| Maglev Hashing | Использование предзаполненной таблицы переходов | Постоянное время поиска O(1), устойчивость | Медленная перегенерация таблицы при сбоях |
Алгоритм Maglev, разработанный Google, строит для каждого узла список предпочтительных позиций в большой таблице (lookup table).
Это обеспечивает мгновенный поиск узла, однако требует значительных вычислительных ресурсов для перегенерации таблицы при добавлении или падении серверов.
Это делает его отличным выбором для стабильных балансировщиков, но менее подходящим для систем с постоянно меняющимся составом узлов.
Заключение
Консистентное хеширование - это стандарт проектирования распределенных систем, где изменения в составе кластера (добавление или сбой узлов) являются нормой. В отличие от классических методов, этот алгоритм минимизирует объем перемещаемых данных при масштабировании. Для корректной работы системы важно правильно подобрать количество виртуальных узлов и использовать производительные хеш-функции, такие как MurmurHash. Это делает процесс расширения инфраструктуры предсказуемым и защищает систему от перегрузок.