
Перевод/заметки Go Production Performance Gotcha - GOMAXPROCS
Недавно мы столкнулись с неприятной проблемой: производительность одной из наших систем оказалась почти в два раза ниже ожидаемого уровня.
После проведения ряда тестов мы выяснили, что причина этого кроется в том, что мы не указали параметр GOMAXPROCS.
Предыстория
Metoro — это платформа для обеспечения прозрачности систем, работающих в Kubernetes. Для сбора данных о кластере и его рабочих нагрузках мы разворачиваем на наблюдаемых кластерах daemonset. Этот демонсет создает на каждом узле pod, под названием node-agent. Этот агент собирает информацию о рабочих нагрузках и отправляет ее за пределы кластера для хранения.
Агент выполняет ряд операций ядра через eBPF, что позволяет автоматически генерировать распределенные трассировки и другую телеметрию. Это означает, что использование процессора агентом зависит от количества запросов, поступающих в/из pod на node. Обычно для обработки 12 000 HTTP-запросов агенту требуется около 1 секунды процессорного времени (на современных хостах EC2).
Проблема
Во время установки нового кластера для клиента мы заметили, что некоторые из наших агентов используют значительно больше процессорного времени, чем мы предполагали. Хосты в этом кластере обрабатывали до 200 тысяч запросов в минуту, и мы ожидали, что для обработки этих запросов агенту потребуется около 17 секунд процессорного времени (28% одного ядра) в минуту. Однако мы обнаружили, что агент использовал 30 секунд (50% одного ядра), что почти в два раза больше, чем ожидалось для такой нагрузки.
К счастью, в Metoro есть профилировщик процессора, основанный на eBPF, который мы можем использовать для проверки использования процессора. Вот что мы обнаружили:
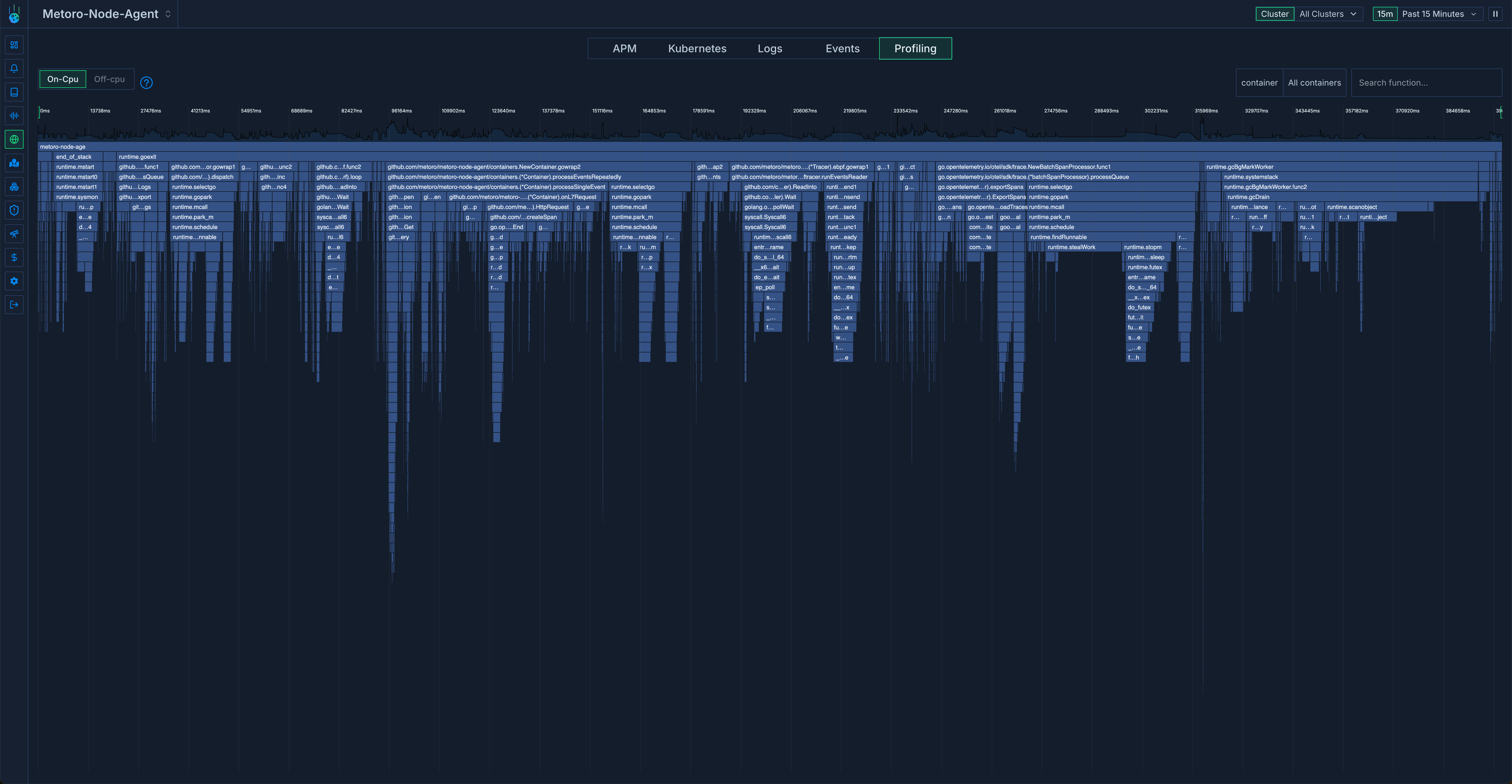
Одна вещь сразу же бросалась в глаза: функции runtime использовали значительное количество процессорного времени. Вот тот же график, но с выделенными функциями runtime:
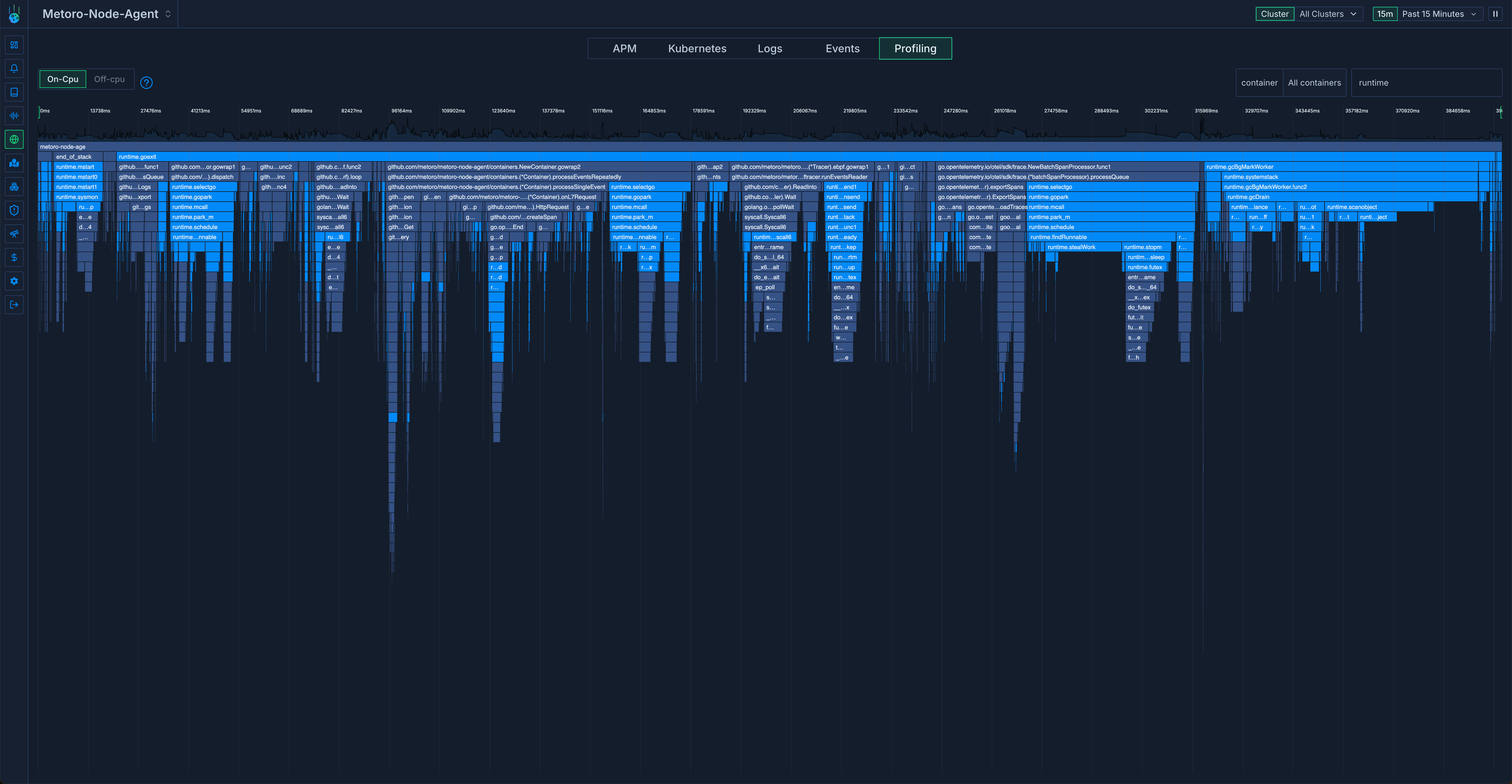
Нагрузка на процессор была распределена между двумя основными процессами:
runtime.schedule- ~30% of cpu usageruntime.gcBgMarkWorker- ~20% of cpu usage
runtime.Schedule отвечает за поиск горутин, которые нужно выполнить, и их запуск в потоке ОС.
runtime.gcBgMarkWorker занимается определением участков памяти, которые могут быть помечены для последующей очистки сборщиком мусора.
Чтобы лучше понять причины происходящего, мы провели эксперимент в dev-кластере, в котором обрабатывалось то же количество запросов. Вот что мы обнаружили:
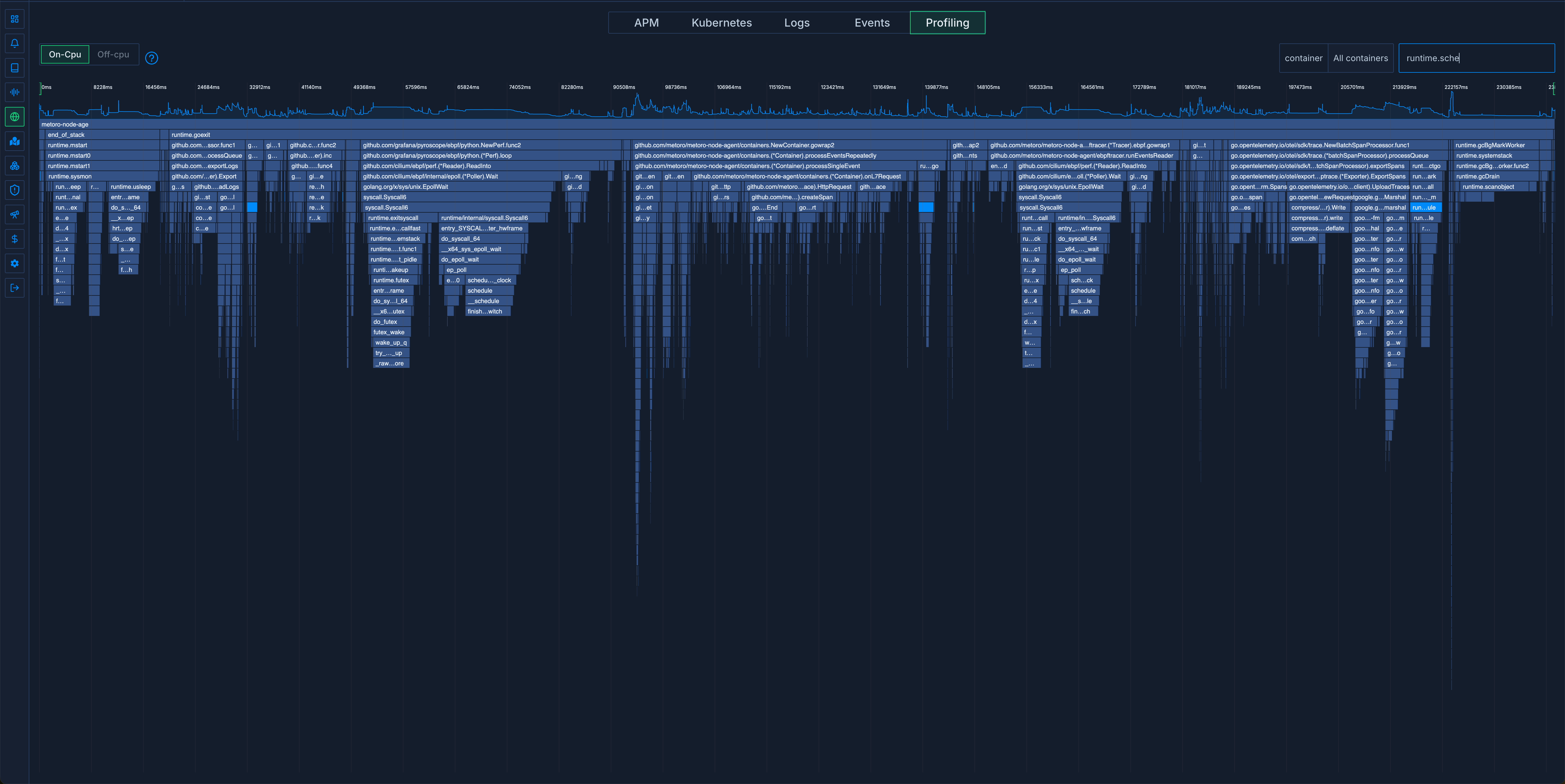
Выделенная область runtime.Schedule - на этот раз всего 5% и runtime.gcBgMarkWorker - еще 6%.
Мы стали искать другие различия в среде, пока не обратили внимание на размер хоста. Агент, который потреблял 50% процессорного времени, работал на хосте с 192 ядрами. В то же время наш собственный хост имел всего 4 ядра.
Мы добавили 192-ядерный хост в наш кластер и провели эксперимент заново. И это сработало! 50% времени было потрачено на две функции runtime.
Это заставило нас задуматься. Почему на более мощном хосте runtime использует в пять раз больше ресурсов процессора, хотя сама программа Go не выполняет никаких дополнительных задач?
После долгих поисков в интернете мы наткнулись на пару проблем на GitHub, в которых связывали использование CPU runtime с параметром GOMAXPROCS.
Согласно документации:
Переменная
GOMAXPROCSограничивает количество потоков операционной системы, которые могут одновременно выполнять user-level Go код. Количество потоков, которые могут быть заблокированы в системных вызовах от имени кода Go, не ограничено; они не учитываются в ограниченииGOMAXPROCS.
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
ncpu вычисляется по-разному в зависимости от ОС. Обычно это количество ядер на хосте, но на самом деле оно может быть немного другим.
Эти две функции: runtime.Schedule и runtime.gcBgMarkWorker масштабируются по количеству процессов используемых программой go, которых на нашем большом хосте 192, а на маленьком - всего 4. Вот почему они используют гораздо больше процессорного времени.
Это значение по умолчанию не особенно полезно, если вы работаете в контейнерной среде. В такой среде, скорее всего, на том же хосте работает множество других контейнеров.
В нашем случае мы по умолчанию ограничиваем количество процессоров на агенте одним ядром, чтобы не влиять на рабочие нагрузки клиентов. Поэтому в нашем случае мы хотим, чтобы GOMAXPROCS был равен 1, так как мы все равно не можем использовать более одного ядра.
Решение
Нам нужно установить GOMAXPROCS на более разумное значение.
- https://github.com/uber-go/automaxprocs - библиотека, которая программно устанавливает
GOMAXPROCSравным cpu-квоте контейнера. - kubernetes downward api - позволяет вам выставлять значения для работающего контейнера через переменные окружения.
Мы постоянно работаем с k8s, поэтому решили использовать downwards api для установки переменной окружения GOMAXPROCS на node-agent контейнере во время развертывания. Выглядит это следующим образом.
env:
- name: GOMAXPROCS
valueFrom:
resourceFieldRef:
resource: limits.cpu
divisor: "1"
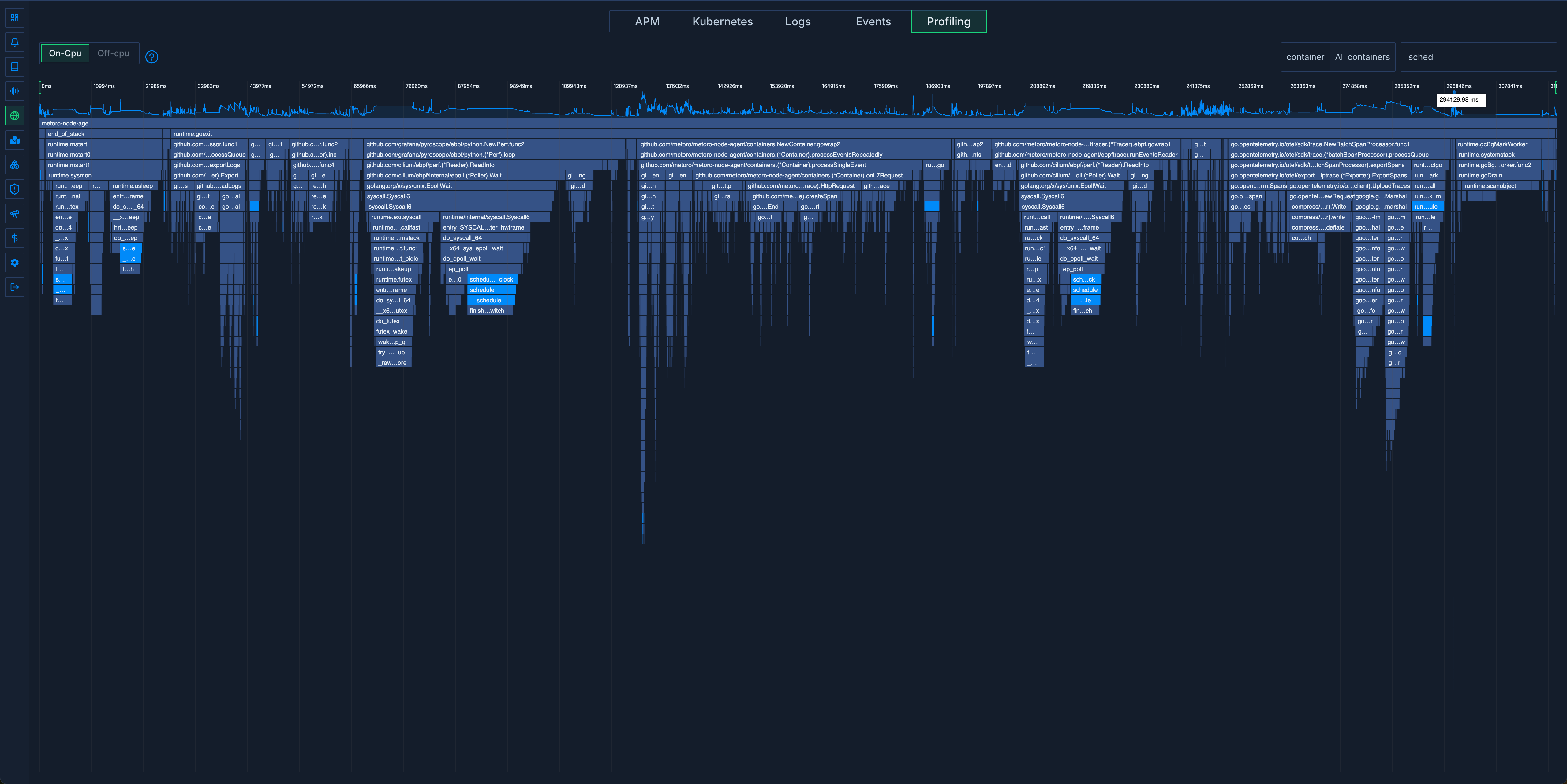
Запустив бенчмарк на нашем 192-ядерном хосте, мы снова получили ожидаемое использование процессора и следующий флейм-граф:
Комментарии в Telegram-группе!