
Перевод/заметки Go Profilers
CPU Profiler
Профилировщик процессора поможет вам определить, какие части вашей кодовой базы потребляют много процессорного времени.
Профилировщиком можно управлять с помощью различных API:
go test -cpuprofile cpu.pprofзапустит ваши тесты и запишет профиль процессора в файл с именемcpu.pprof.pprof.StartCPUProfile(w)записывает профиль процессора вw, который охватывает промежуток времени до вызоваpprof.StopCPUProfile().import _ "net/http/pprof"позволяет запросить профиль процессора за 30 секундGET /debug/pprof/profile?seconds=30стандартного http-сервера, который можно запустить черезhttp.ListenAndServe("localhost:6060", nil).runtime.SetCPUProfileRate()позволяет управлять частотой выборки профилировщика процессора.runtime.SetCgoTraceback()можно использовать для получения трассировки стека в коде cgo. benesch/cgosymbolizer имеет реализацию для Linux и macOS.
Пример с pprof.StartCPUProfile(w):
file, _ := os.Create("./cpu.pprof")
pprof.StartCPUProfile(file)
defer pprof.StopCPUProfile()
Независимо от того, как вы активируете профилировщик процессора, результирующий профиль будет представлять собой таблицу трассировок стека, отформатированную в двоичном формате pprof. Упрощенная версия такой таблицы показана ниже:
| stack trace | samples/count | cpu/nanoseconds |
|---|---|---|
| main;foo | 5 | 50000000 |
| main;foo;bar | 3 | 30000000 |
| main;foobar | 4 | 40000000 |
Профилировщик CPU фиксирует эти данные, запрашивая у операционной системы мониторинг использования CPU приложением и посылая ему сигнал SIGPROF за каждые 10 мс потребляемого им процессорного времени. ОС также включает в этот мониторинг время, потребляемое ядром от имени приложения. Поскольку частота отправки сигнала зависит от потребления процессора, она динамична и может составлять до N * 100 Гц, где N - количество логических ядер процессора в системе. Когда поступает сигнал SIGPROF, обработчик сигнала Go захватывает трассировку стека активной в данный момент goroutine и увеличивает соответствующие значения в профиле. Значение cpu/nanoseconds в настоящее время напрямую выводится из количества выборок, поэтому оно избыточно, но удобно.
CPU Profiler Labels
Классная особенность профилировщика процессора Go заключается в том, что вы можете прикрепить произвольные пары ключ-значение к горутине. Эти метки будут унаследованы любой порожденной от нее goroutine и отобразятся в результирующем профиле.
Рассмотрим приведенный ниже пример, который выполняет некоторую работу work() от имени пользователя. Используя API pprof.Labels() и pprof.Do(), мы можем ассоциировать user с той горутиной, которая выполняет функцию work(). Кроме того, эти метки автоматически наследуются любой горутиной, порожденной в том же блоке кода, например, горутиной backgroundWork().
func work(ctx context.Context, user string) {
labels := pprof.Labels("user", user)
pprof.Do(ctx, labels, func(_ context.Context) {
go backgroundWork()
directWork()
})
}
Полученный профиль будет содержать новый столбец с метками и может выглядеть примерно так:
| stack trace | label | samples/count | cpu/nanoseconds |
|---|---|---|---|
| main.backgroundWork | user:bob | 5 | 50000000 |
| main.backgroundWork | user:alice | 2 | 20000000 |
| main.work;main.directWork | user:bob | 4 | 40000000 |
| main.work;main.directWork | user:alice | 3 | 30000000 |
При просмотре того же профиля с помощью представления Graph в pprof метки также будут отображаться:
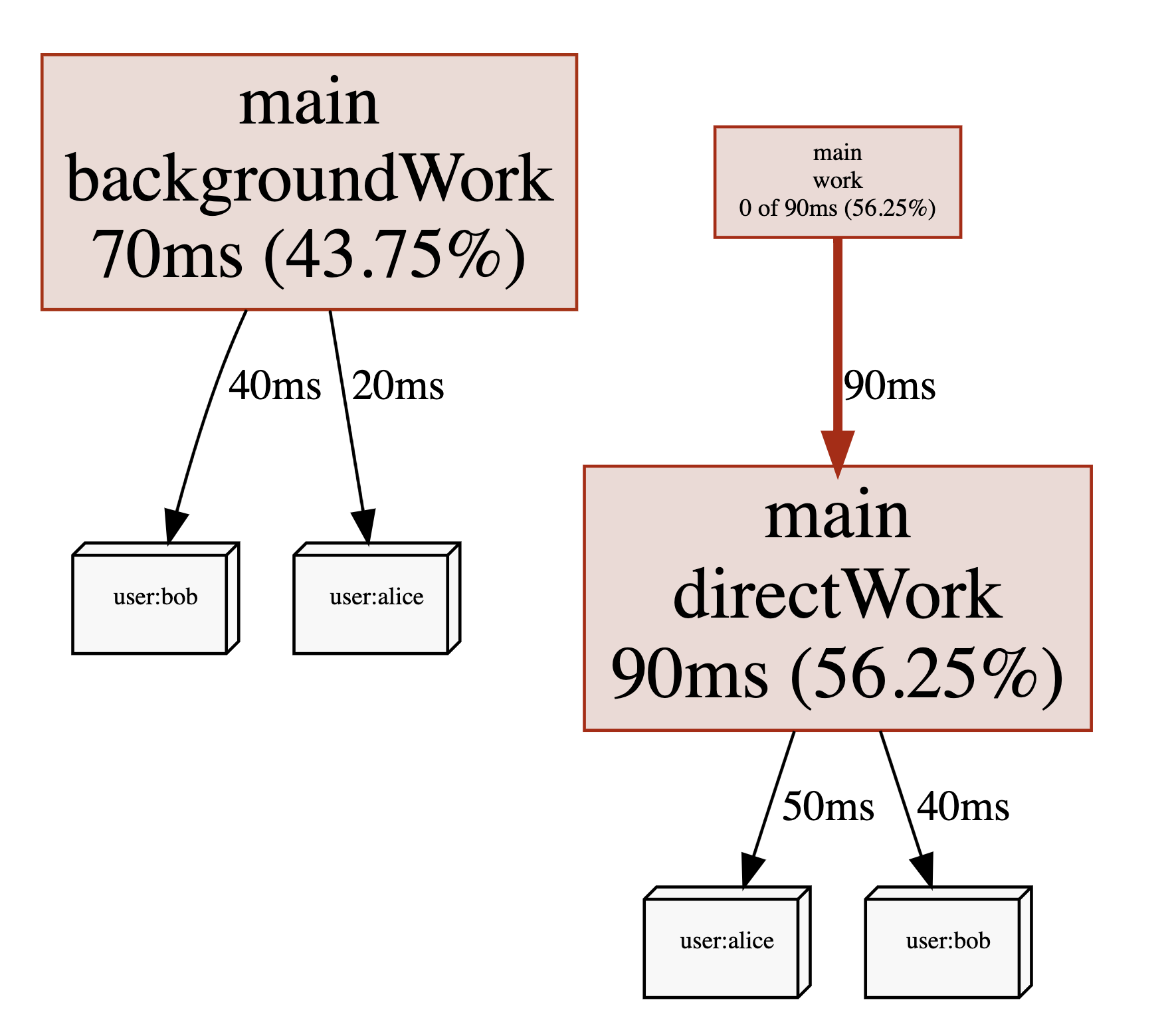
Как использовать эти метки, зависит только от вас. Вы можете включить в них такие вещи, как user ids, request ids, http endpoints, subscription plan или другие данные, которые позволят вам лучше понять, какие типы запросов вызывают высокую загрузку процессора, даже если они обрабатываются одними и теми же путями кода. При этом использование меток приведет к увеличению размера файлов pprof. Поэтому вам, вероятно, следует начать с меток с низкой кардинальностью, таких как endpoints, а затем перейти к меткам с высокой кардинальностью, когда вы убедитесь, что они не влияют на производительность вашего приложения.
CPU Utilization
Поскольку частота профилировщика CPU адаптируется к количеству CPU, которое потребляет ваша программа, вы можете получить данные о загрузке CPU из профилей CPU. Фактически, pprof сделает это автоматически. Например, приведенный ниже профиль был взят из программы, которая использовала процессор в среднем на 147,77%:
$ go tool pprof guide/cpu-utilization.pprof
Type: cpu
Time: Sep 9, 2021 at 11:34pm (CEST)
Duration: 1.12s, Total samples = 1.65s (147.77%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
Другим популярным способом выражения загрузки процессора являются ядра процессора. В приведенном выше примере программа использовала в среднем 1,47 ядра процессора в течение периода профилирования.
System Calls в CPU Profiles
Если вы видите, что системные вызовы, такие как syscall.Read() или syscall.Write(), используют много времени в профиле процессора, обратите внимание, что это только процессорное время, потраченное внутри этих функций в ядре. Само время ввода/вывода не отслеживается. Расход времени на системные вызовы обычно является признаком того, что их слишком много, так что, возможно, увеличение размера буфера может помочь. Для более сложных ситуаций, подобных этой, вы должны рассмотреть возможность использования Linux perf, поскольку он также может показать вам трассировку стека ядра, которая может дать вам дополнительные подсказки.
Ограничения CPU Profiler
Существует несколько известных проблем и ограничений профилировщика процессора, о которых вы должны знать:
- 🐞 GH #35057: Профили процессора, снятые с помощью Go версии <= 1.17, становятся несколько неточными для программ, использующих более 2,5 ядер процессора. В общем случае общая загрузка процессора будет занижена, а скачки нагрузки также могут быть недооценены в результирующем профиле. Это исправлено в Go 1.18. А пока вы можете попробовать использовать Linux perf в качестве обходного пути.
- 🐞 Лейблы профилировщика в версиях Go <= 1.17 страдали от нескольких ошибок.
- GH #48577 and CL 367200: Отсутствовали лейблы для горутин, выполняющихся на системном стеке, выполняющих код на языке C или выполняющих системные вызовы.
- CL 369741: В первой партии сэмплов в профиле процессора была допущена ошибка, приведшая к неправильному распределению лейблов.
- CL 369983: Системные goroutines, созданные от имени пользовательских goroutines (например, для сборки мусора), некорректно наследовали лейблы своих родителей.
- Вы можете вызвать
runtime.SetCPUProfileRate()чтобы настроить скорость профилирования процессора перед вызовомruntime.StartCPUProfile(). При этом будет выведено предупреждениеruntime: cannot set cpu profile rate until previous profile has finished. Однако это все еще работает в рамках ограничения, связанного с вышеупомянутой ошибкой. https://github.com/golang/go/issues/40094, https://github.com/golang/go/issues/42502. - Максимальное количество вызовов вложенных функций, которое может быть зафиксировано в трассировке стека профилировщиком CPU, в настоящее время составляет
64. Если в вашей программе используется много рекурсий или других схем, которые приводят к большой глубине стека, профиль процессора будет включать усеченные трассировки стека. Это означает, что вы пропустите части цепочки вызовов, которые привели к функции, активной в момент взятия образца.
Memory Profiler
Профилировщик памяти Go может помочь вам определить, какие части вашей кодовой базы выполняют много аллокаций на кучи, а также сколько из этих аллокаций было доступно во время последней сборки мусора. Из-за этого профиль, создаваемый профилировщиком памяти, также часто называют профилем кучи.
Управление памятью, часто занимает 20-30% процессорного времени, потребляемого процессами Go. Кроме того, устранение аллокаций из кучи может иметь эффекты второго порядка, которые ускоряют другие части вашего кода из-за уменьшения количества кэш-трешинга, который происходит, когда сборщику мусора приходится сканировать кучу. Это означает, что оптимизация работы с памятью часто может иметь больще эффекта, чем оптимизация путей кода, связанных с процессором.
Вы можете управлять профилировщиком памяти с помощью различных API:
go test -memprofile mem.pprofзапустит ваши тесты и запишет профиль памяти в файл с именемmem.pprof.pprof.Lookup("allocs").WriteTo(w, 0)записывает вwпрофиль памяти, содержащий события выделения с момента запуска процесса.import _ "net/http/pprof"позволяет запросить профиль памяти на 30 секундGET /debug/pprof/allocs?seconds=30стандартного http-сервера, который можно запустить черезhttp.ListenAndServe("localhost:6060", nil). Внутри это также называется дельта-профилем.runtime.MemProfileRateпозволяет управлять частотой выборки профилировщика памяти.
Пример с pprof.Lookup("allocs").WriteTo(file, 0):
file, _ := os.Create("./mem.pprof")
defer pprof.Lookup("allocs").WriteTo(file, 0)
defer runtime.GC()
Независимо от того, как вы активируете профилировщик памяти, результирующий профиль будет представлять собой таблицу трассировок стека, отформатированную в двоичном формате pprof. Упрощенная версия такой таблицы показана ниже:
| stack trace | alloc_objects/count | alloc_space/bytes | inuse_objects/count | inuse_space/bytes |
|---|---|---|---|---|
| main;foo | 5 | 120 | 2 | 48 |
| main;foo;bar | 3 | 768 | 0 | 0 |
| main;foobar | 4 | 512 | 1 | 128 |
Профиль памяти содержит две основные части информации:
alloc_*: Количество аллокаций, сделанных вашей программой со старта процесса (или период профилирования для дельта-профилей).inuse_*: Количество аллокаций, сделанных вашей программой, которые были доступны во время последнего GC.
Вы можете использовать эту информацию в различных целях. Например, вы можете использовать данные alloc_*, чтобы определить, какие пути кода могут производить много мусора для GC, а просмотр данных inuse_* с течением времени может помочь вам в расследовании утечек памяти или высокого использования памяти вашей программой.
Allocs vs Heap Profile
Функция pprof.Lookup(), а также пакет net/http/pprof раскрывают профиль памяти под двумя именами: allocs и heap. Оба профиля содержат одинаковые данные, разница лишь в том, что для профиля allocs в качестве типа выборки по умолчанию задано alloc_space/bytes, а для профиля heap по умолчанию задано inuse_space/bytes. Это используется инструментом pprof, чтобы решить, какой тип выборки показывать по умолчанию.
Memory Profiler Sampling
Для снижения накладных расходов профилировщик памяти использует пуассоновскую выборку, так что в среднем только одно выделение каждые 512KiB вызывает отслеживание стека и добавление его в профиль. Однако перед записью профиля в конечный файл pprof runtime масштабирует собранные значения выборки, разделив их на вероятность выборки. Это означает, что количество зарегистрированных выделений должно быть хорошей оценкой фактического количества аллокаций, независимо от используемого runtime.MemProfileRate.
Для профилирования в продакшене, как правило, не нужно изменять частоту выборки. Единственная причина для этого - если вы беспокоитесь, что в ситуациях, когда происходит очень мало распределений, собирается недостаточно образцов.
Memory Inuse vs RSS
Частая путаница - посмотреть на общий объем памяти, о котором сообщает тип выборки inuse_space/bytes, и заметить, что он не совпадает с использованием памяти RSS, о котором сообщает операционная система. Этому есть разные причины:
- RSS включает в себя гораздо больше, чем просто использование памяти кучи Go по определению, например, память, используемую стеками горутин, исполняемым файлом программы, разделяемыми библиотеками, а также память, выделяемую функциями C.
- GC может решить не возвращать свободную память в ОС немедленно, но это должно стать меньшей проблемой после runtime changes in Go 1.16.
- Go использует non-moving GC, поэтому в некоторых случаях свободная память кучи может быть фрагментирована таким образом, что Go не сможет освободить ее для ОС.
Memory Profiler Implementation
Приведенный ниже псевдокод должен отразить основные аспекты реализации профилировщика памяти, чтобы вы могли лучше понять его. Как вы можете видеть, функция malloc() внутри рантайма Go использует poisson_sample(size), чтобы определить, нужно ли делать выборку аллокации. Если да, то берется трассировка стека s и используется в качестве ключа в хэш-карте mem_profile для увеличения счетчиков allocs и alloc_bytes. Кроме того, вызов track_profiled(object, s) помечает object как выборочную аллокацию в куче и связывает с ним трассировку стека s.
func malloc(size):
object = ... // allocation magic
if poisson_sample(size):
s = stacktrace()
mem_profile[s].allocs++
mem_profile[s].alloc_bytes += size
track_profiled(object, s)
return object
Когда GC определяет, что пришло время освободить аллокацию, он вызывает sweep(), которая использует is_profiled(object), чтобы проверить, помечен ли object как объект выборки. Если да, то он извлекает трассировку стека s, которая привела к аллокации, и увеличивает счетчики frees и free_bytes для него внутри mem_profile.
func sweep(object):
if is_profiled(object)
s = alloc_stacktrace(object)
mem_profile[s].frees++
mem_profile[s].free_bytes += sizeof(object)
// deallocation magic
Сами счетчики free_* не включаются в итоговый профиль памяти. Вместо этого они используются для расчета счетчиков inuse_* в профиле путем простого вычитания allocs - frees. Кроме того, итоговые выходные значения масштабируются путем деления их на вероятность выборки.
Ограничения Memory Profiler
- 🐞 GH #49171: Дельта-профили (получаемые, например, с помощью
GET /debug/pprof/allocs?seconds=60) могут сообщать об отрицательных количествах аллокаций из-за ошибки символизации, связанной с инлайновыми замыканиями в Go 1.17. Эта ошибка исправлена в Go 1.18. runtime.MemProfileRateдолжно быть изменено только один раз, как можно раньше при запуске программы; например, в началеmain(). Запись этого значения по своей сути является небольшой гонкой данных, и его многократное изменение во время выполнения программы приведет к созданию некорректных профилей.- При отладке потенциальных утечек памяти профилировщик памяти может показать, где были созданы эти аллокации, но не может показать, какие ссылки их поддерживают. За прошедшие годы было предпринято несколько попыток решить эту проблему, но ни одна из них не работает в последних версиях Go.
- Метки CPU Profiler Labels или подобные им не поддерживаются профилировщиком памяти. Добавить эту возможность в текущую реализацию сложно, так как это может привести к утечке памяти во внутренней хэш-карте, хранящей данные профилирования памяти.
- Аллокации, сделанные C-кодом cgo, не отображаются в профиле памяти.
- Данные профиля памяти могут иметь возраст до двух циклов сборки мусора. Если вы хотите получить более последовательный снимок в момент времени, вызовите
runtime.GC()перед запросом профиля памяти. net/http/pprof принимает аргумент?gc=1для этой цели. Дополнительную информацию можно найти в документации по runtime.MemProfile(), а также в комментарии кmemRecordвmprof.go. - Максимальное количество вложенных вызовов функций, которые могут быть зафиксированы в трассировке стека профилировщиком памяти, в настоящее время составляет
32 - Для внутренней хэш-карты, содержащей профиль памяти, нет ограничений по размеру. Это означает, что она будет расти до тех пор, пока не покроет все пути аллокации в вашей кодовой базе. На практике это не является проблемой, но может выглядеть как небольшая утечка памяти, если вы наблюдаете за использованием памяти вашим процессом.
Block Profiler
Профилировщик блокировок в Go измеряет, сколько времени ваши горутины проводят вне процессора в ожидании операций с каналами и мьютексами, предоставляемых пакетом sync. Следующие операции Go подключаются к профилировщику:
selectchan sendchan receivesemacquire(Mutex.Lock,RWMutex.RLock,RWMutex.Lock,WaitGroup.Wait)notifyListWait(Cond.Wait)
Профили блокировок не учитывают время ожидания I/O, Sleep, GC и другие состояния ожидания. Кроме того, события блокировки не записываются до их завершения, поэтому профиль нельзя использовать для отладки того, почему программа на Go в данный момент зависла. Последнее можно определить с помощью Goroutine Profiler.
Вы можете управлять профилировщиком с помощью различных API:
go test -blockprofile block.pprofзапустит ваши тесты и запишет профиль, фиксирующий каждое событие блокировки, в файл с именемblock.pprof.runtime.SetBlockProfileRate(rate)позволяет включить и контролировать частоту дискретизации профилировщика.pprof.Lookup("block").WriteTo(w, 0)записывает вwпрофиль, содержащий блокирующие события с момента начала процесса.import _ "net/http/pprof"позволяет запросить профиль длительностью 30 секунд, обратившись кGET /debug/pprof/block?seconds=30стандартного http-сервера, который можно запустить черезhttp.ListenAndServe("localhost:6060", nil). Внутри системы это также называется дельта-профилем.
Пример:
runtime.SetBlockProfileRate(100_000_000) // WARNING: Can cause some CPU overhead
file, _ := os.Create("./block.pprof")
defer pprof.Lookup("block").WriteTo(file, 0)
Независимо от того, как вы активируете профилировщик, результирующий профиль будет представлять собой таблицу трассировок стека, отформатированную в двоичном формате pprof. Упрощенная версия такой таблицы показана ниже:
| stack trace | contentions/count | delay/nanoseconds |
|---|---|---|
| main;foo;runtime.selectgo | 5 | 867549417 |
| main;foo;bar;sync.(*Mutex).Lock | 3 | 453510869 |
| main;foobar;runtime.chanrecv1 | 4 | 5351086 |
Block Profiler Implementation
Приведенный ниже псевдокод должен отразить основные аспекты реализации профилировщика блокировок, чтобы вы могли лучше понять его. При отправке сообщения на канал, т.е. ch <- msg, Go вызывает функцию chansend() в runtime, которая показана ниже. Если канал ready() к приему сообщения, то send() происходит немедленно. В противном случае профилировщик фиксирует время начала блокирующего события и использует функцию wait_until_ready(), чтобы попросить планировщик переместить горутину с процессора до тех пор, пока канал не будет готов. Как только канал готов, определяется duration блокировки и используется функцией random_sample() вместе с частотой выборки, чтобы решить, нужно ли записывать это событие блока. Если да, то перехватывается текущая трассировка стека s и используется в качестве ключа в хэш-карте block_profile для увеличения значений count и delay. После этого происходит собственно операция send().
func chansend(channel, msg):
if ready(channel):
send(channel, msg)
return
start = now()
wait_until_ready(channel) // Off-CPU Wait
duration = now() - start
if random_sample(duration, rate):
s = stacktrace()
// note: actual implementation is a bit trickier to correct for bias
block_profile[s].contentions += 1
block_profile[s].delay += duration
send(channel, msg)
Функция random_sample выглядит так, как показано ниже. Если включен профилировщик, все события, в которых duration >= rate, будут захвачены, а более короткие события имеют шанс быть захваченными по соотношению duration/rate.
func random_sample(duration, rate):
if rate <= 0 || (duration < rate && duration/rate > rand(0, 1)):
return false
return true
Другими словами, если вы установите значение rate равным 10.000 (единица измерения - наносекунды), будут захвачены все блокирующие события длительностью 10 µsec и более. Дополнительно фиксируются 10% событий длительностью 1 µsec, 1% событий длительностью 100 nanoseconds и так далее.
Block vs Mutex Profiler
И профилировщик блокировок, и мьютексный профилировщик сообщают о времени ожидания на мьютексах. Разница в том, что профилировщик блокировок фиксирует время ожидания получения Lock(), а мьютексный профилировщик фиксирует время ожидания другой горутины, прежде чем Unlock() позволит ей продолжить работу.
Другими словами, профилировщик блокировок показывает, какие горутины испытывают повышенную задержку из-за споров по мьютексам, а мьютексный профилировщик показывает горутины, которые удерживают блокировки, вызывающие споры.
Ограничения Block Profiler
- Профилировщик блокировок может вызывать значительную нагрузку на процессор, поэтому рекомендуется использовать его только для разработки и тестирования. Если вам необходимо использовать его на проде, начните с очень высокой скорости, возможно, 100 миллионов, и снижайте ее только при необходимости. В прошлом в этом руководстве рекомендовалась скорость 10000 как безопасная, но мы видели, что рабочие нагрузки страдали от накладных расходов до 4% при таких настройках, и даже скорости до 10 миллионов было недостаточно для значительного снижения накладных расходов.
- Профилировщик блокировок охватывают лишь небольшое подмножество Off-CPU waiting states, в которые может перейти горутина.
- В Go 1.17 исправлена давняя ошибка смещения выборки в профилировщике блокировок.
Mutex profiler
Профилировщик мьютексов измеряет, сколько времени горутины тратят на блокировку других горутин. Другими словами, он измеряет источники блокировки. Профилировщик мьютексов может фиксировать блокировки, исходящие от sync.Mutex и sync.RWMutex.
Профили мьютексов не учитывают другие источники конфликтов, такие как sync.WaitGroup, sync.Cond или доступ к дескрипторам файлов. Кроме того, мьютекс не регистрируется до тех пор, пока мьютекс не будет разблокирован, поэтому профиль мьютекса нельзя использовать для отладки того, почему программа на Go зависла в данный момент. Последнее можно определить с помощью Goroutine Profiler.
Вы можете управлять профилировщиком мьютексов с помощью различных API:
go test -mutexprofile mutex.pprofruntime.SetMutexProfileRate(rate)позволяет включить и контролировать частоту выборки профилировщика мьютексов. Если вы установите частоту выборкиR, то будет фиксироваться в среднем1/Rсобытий борьбы с мьютексом. Если частота равна0или меньше, то ничего не фиксируется.pprof.Lookup("mutex").WriteTo(w, 0)import _ "net/http/pprof"позволяет запросить профиль длительностью 30 секунд, обратившись кGET /debug/pprof/mutex?seconds=30
Пример:
runtime.SetMutexProfileFraction(100)
file, _ := os.Create("./mutex.pprof")
defer pprof.Lookup("mutex").WriteTo(file, 0)
Независимо от того, как вы активируете профилировщик, результирующий профиль будет представлять собой таблицу трассировок стека, отформатированную в двоичном формате pprof. Упрощенная версия такой таблицы показана ниже:
| stack trace | contentions/count | delay/nanoseconds |
|---|---|---|
| main;foo;sync.(*Mutex).Unlock | 5 | 867549417 |
| main;bar;baz;sync.(*Mutex).Unlock | 3 | 453510869 |
| main;foobar;sync.(*RWMutex).RUnlock | 4 | 5351086 |
Mutex Profiler Implementation
Профилировщик мьютексов реализуется путем записи времени от момента, когда горутина пытается получить блокировку (например, mu.Lock()), до момента, когда блокировка освобождается горутиной, удерживающей блокировку (например, mu.Unlock()). Сначала горутина вызывает semacquire(), чтобы получить блокировку, и записывает время, когда она начала ждать, если блокировка уже удерживается. Когда горутина, удерживающая блокировку, освобождает ее, вызывая semrelease(), горутина ищет следующую горутину, ожидающую блокировку, и смотрит, сколько времени та горутина провела в ожидании. Текущая скорость профилирования мьютекса используется для случайного решения, записывать ли это событие. Если случайный выбор сделан, то время блокировки записывается в хэш-таблицу mutex_profile с ключом от стека вызовов, где горутина освободила блокировку.
func semacquire(lock):
if lock.take():
return
start = now()
waiters[lock].add(this_goroutine(), start)
wait_for_wake_up()
func semrelease(lock):
next_goroutine, start = waiters[lock].get()
if !next_goroutine:
// If there weren't any waiting goroutines, there is no contention to record
return
duration = now() - start
if rand(0,1) < 1 / rate:
s = stacktrace()
mutex_profile[s].contentions += 1
mutex_profile[s].delay += duration
wake_up(next_goroutine)
Mutex Profiler Limitations
Профилировщик мьютексов имеет ограничения, аналогичные профилировщику блокировок:
- Максимальное количество вложенных вызовов функций, которые могут быть зафиксированы в трассировке стека профилировщиком мьютексов, в настоящее время составляет
32 - Для внутренней хэш-таблицы, в которой хранится профиль мьютексов, нет ограничений по размеру. Это означает, что она будет расти до тех пор, пока не покроет все блокирующие пути кода в вашей кодовой базе. На практике это не является проблемой, но может выглядеть как небольшая утечка памяти, если вы наблюдаете за использованием памяти вашим процессом.
- CPU Profiler Labels и подобные им не поддерживаются мьютексным профилировщиком. Добавить эту возможность в текущую реализацию сложно, так как это может привести к утечке памяти во внутренней хэш-таблице, хранящей данные профилирования памяти.
- Подсчеты contention и время задержки в профиле мьютекса корректируются во время создания отчета на основе последней настроенной частоты выборки, а не во время выборки. В результате программы, которые изменяют долю профиля мьютекса в середине выполнения, могут увидеть искаженные подсчеты и задержки.
Комментарии в Telegram-группе!