
Перевод/заметки Container CPU Requests & Limits Explained with GOMAXPROCS Tuning
Обзор cgroups
Kubernetes использует так называемые cgroups (сокращение от control groups) для управления и контроля использования ресурсов, таких как процессор и память, для каждого pod и контейнера на узле. Это можно представить как многоуровневую структуру:
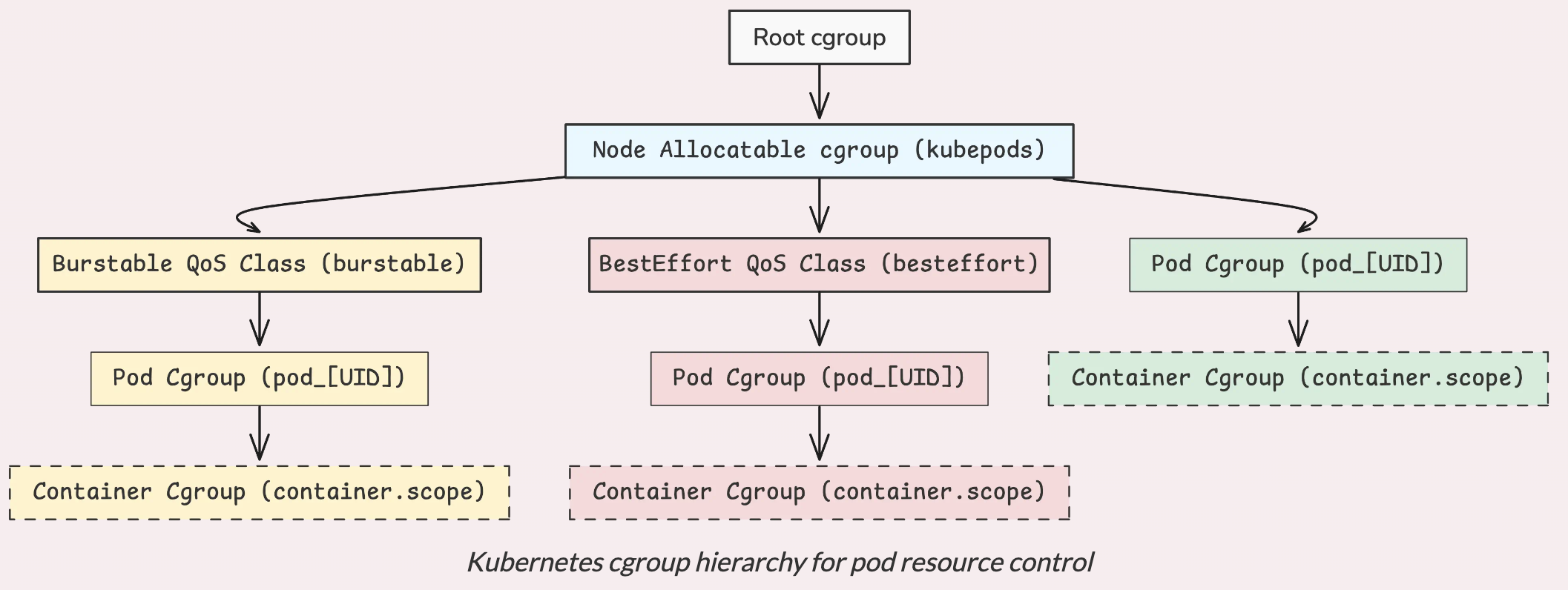
На вершине структуры находится root cgroup. Это начальная точка. Далее Kubernetes (через kubelet, который является главным агентом, запущенным на каждом узле) создает cgroup на уровне узла, обычно называемую kubepods, для управления всеми рабочими нагрузками.
Далее все делится на классы QoS (сокращение от Quality of Service — качество обслуживания). Каждый pod попадает в один из трёх классов в зависимости от того, как он определяет свои запросы и ограничения на процессор и память:
- Guaranteed pod имеет запросы на процессор и память, которые точно соответствуют их лимитам. Они получают наилучшую производительность и приоритет.
- У Burstable pod запросы ниже лимитов, поэтому он гарантированно получает базовый уровень ресурсов. Однако, если есть свободное место, он может использовать больше ресурсов.
- В Best-Effort pod не определены ни запросы, ни лимиты. Он использует все доступные ресурсы и в первую очередь страдает от троттлинга(throttled) или вытеснения, когда ситуация становится напряжённой.
Если у pod одинаковые запросы и лимиты процессора, но разные запросы и лимиты памяти, он не считается Guaranteed.
Почему это важно? Когда у узла заканчиваются ресурсы, Kubernetes использует эти классы QoS, чтобы определить, какие pod замедлить или остановить в первую очередь. Например, при нехватке памяти первыми уходят Best-Effort, затем Burstable, а Guaranteed держатся дольше всех.
За кулисами класс QoS влияет на показатель OOM(Out Of Memory), который влияет на то, какие процессы ядро Linux убивает первыми, когда память вот-вот закончится.
Чем ниже показатель OOM, тем меньше вероятность того, что процесс будет остановлен:
-
Guaranteed containers обычно имеют показатель OOM
-997. Это очень низкий показатель, поэтому вероятность их отключения низкая. -
Burstable containers имеют показатель от
2до1000. Чем больше запрос, тем ниже ваш показатель. -
Best-Effort containers имею больше
1000и первые на отключении. -
Eviction: Этим занимается
kubelet. Это более безопасный процесс - Kubernetes дает pod время на постепенное завершение работы. -
OOM kill: В ядре Linux это происходит, когда заканчивается свободная память. Процесс завершается без предупреждения и без возможности восстановления — просто исчезает.
Как только pod попадает на ноду, kubelet создает для него новую cgroup с требуемым классом QoS. Затем, при запуске контейнерной среды, контейнеры помещаются в свои собственные cgroup внутри cgroup pod.
Настройка ресурсов происходит следующим образом:
- CPU requests преобразуются в
cpu.shares(для cgroup v1) илиcpu.weight(для cgroup v2). - CPU limits становятся в
cpu.cfs_quota_usсcpu.cfs_period_us(v1) или простоcpu.max(v2)
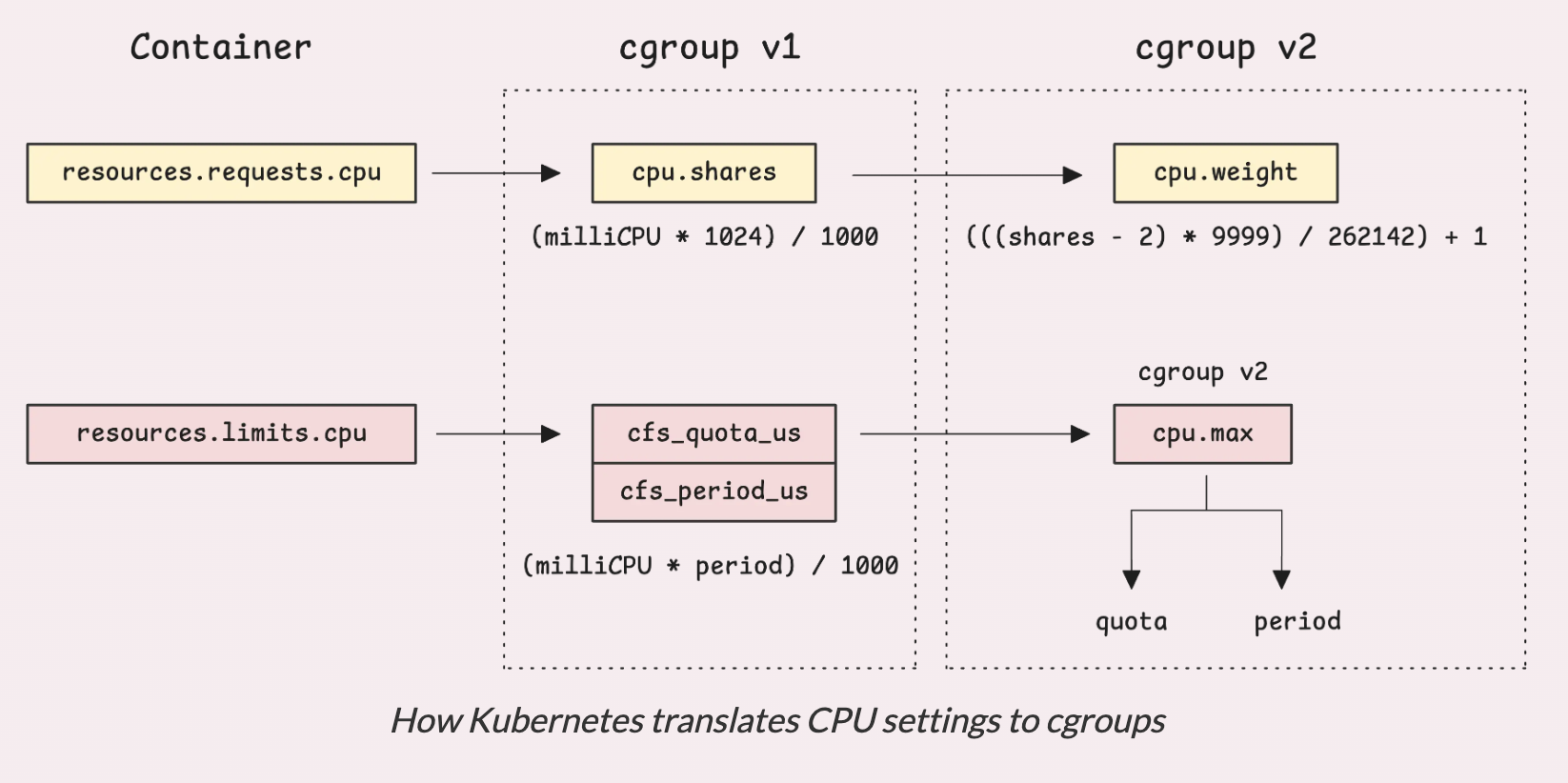
В этом процессе участвуют два ключевых компонента: ядро Linux и Kubernetes.
- Ядро Linux создает виртуальную файловую систему cgroups в каталоге
/sys/fs/cgroup. По сути, это интерфейс, с помощью которого процессы могут настраивать и контролировать распределение ресурсов, таких как процессор и память. Таким образом, именно ядро создает все те файлы, которые вы могли видеть -cpu.max,cpu.cfs_quota_us,cpu.cfs_period_us,cpu.sharesи так далее. - Kubernetes и среда выполнения контейнеров (например, containerd или CRI-O) делают две основные вещи:
- Они создают иерархическую структуру каталогов в
/sys/fs/cgroup/. Эта структура предназначена для упорядочивания подов и контейнеров в понятном для ядра виде. Пути к файлам будут выглядеть примерно так:/sys/fs/cgroup/kubepods/pod{UID}/{container-UID}. - Затем они обрабатывают данные, которые вы указали в спецификациях pod в разделах
resources.*.cpuиresources.*.memory. Они преобразуют эти значения в нужный формат и сохраняют их в файлах ядра. Например, Kubernetes может сохранить ограничения на использование процессора в файле/sys/fs/cgroup/kubepods/pod{UID}/{container-UID}/cpu.max.
- Они создают иерархическую структуру каталогов в
Вы можете убедиться в этом самостоятельно, зайдя на ноду. Откройте папку /sys/fs/cgroup/, и вы увидите структуру, соответствующую описанному ранее:
/sys/fs/cgroup/kubepods/burstable/pod03ca2395-...-39011eb41a40
├── cpu.max: max 100000
├── cpu.weight: 4
├── memory.max: 536870912
│
├── /sys/fs/cgroup/kubepods/burstable/pod03ca2395-...-39011eb41a40/098b...2abe
│ ├── cpu.max: max 100000
│ ├── cpu.weight: 4
│ └── memory.max: 536870912
│
└── /sys/fs/cgroup/kubepods/burstable/pod03ca2395-...-39011eb41a40/984d...8aba
├── cpu.max: max 100000
├── cpu.weight: 1
└── memory.max: max
Даже если в вашем pod всего 1 контейнер, вы, вероятно, все равно увидите 2 каталога: один для вашего контейнера, а другой для pause container.
В Kubernetes есть инструмент под названием CPU Manager, который поддерживает две политики: none и static. На данный момент мы будем использовать политику none, так как она является стандартной.
С помощью static функции Kubernetes может предоставить определённым контейнерам эксклюзивный доступ к ядрам процессора. Однако это возможно только в том случае, если контейнер:
- Находится в классе Guaranteed QoS
- Требуется полное количество процессоров (например,
1или2, а не0,5).
Допустим, у вас есть приложение, чувствительное к задержкам(latency-sensitive), которому нужна стабильная производительность. Вы можете запустить его в Guaranteed pod, который запросит 2 процессора. CPU Manager назначит этому контейнеру 2 выделенных ядра CPU. Никому другому не будет разрешено работать на этих ядрах. Это очень полезно для приложений, которые плохо работают с разделением процессора или нуждаются в сильной локальности кэша.
Все остальные контейнеры - Burstable, Best-Effort и Guaranteed с дробными запросами на процессор - делят между собой остальные ядра обычным образом, используя CFS (Completely Fair Scheduler).
CPU Request
Политика none используется Kubernetes по умолчанию. При такой настройке распределение CPU обрабатывается Completely Fair Scheduler (CFS) ядра Linux. CFS распределяет CPU время между запущенными процессами - контейнеры делят между собой CPU ядра, а ядро Linux решает, кто сколько времени и когда получит.
Например, у вас есть четырёхъядерный сервер, на котором запущено несколько контейнеров. Каждый из этих контейнеров может работать на любом из ядер. Ядро Linux распределяет их поровну, в зависимости от потребностей и приоритетов.
Когда вы устанавливаете запрос CPU (resources.requests.cpu) в спецификации pod, вы влияете на две вещи:
1. Поведение планировщика
Это минимальное количество CPU, которое должен получить pod, чтобы быть запланированным на узле.
Планировщик Kubernetes анализирует запросы на CPU всех размещаемых pod и проверяет, достаточно ли незарезервированной мощности процессора на узле для удовлетворения этих запросов. Если нет, то pod может либо ожидать, либо быть запланирован на другой узел.
Допустим, у вас есть узел с 3 ядрами, и вы пытаетесь разместить три pod с разными запросами на процессор: A запрашивает 1,5, B - 1, а C - 1.
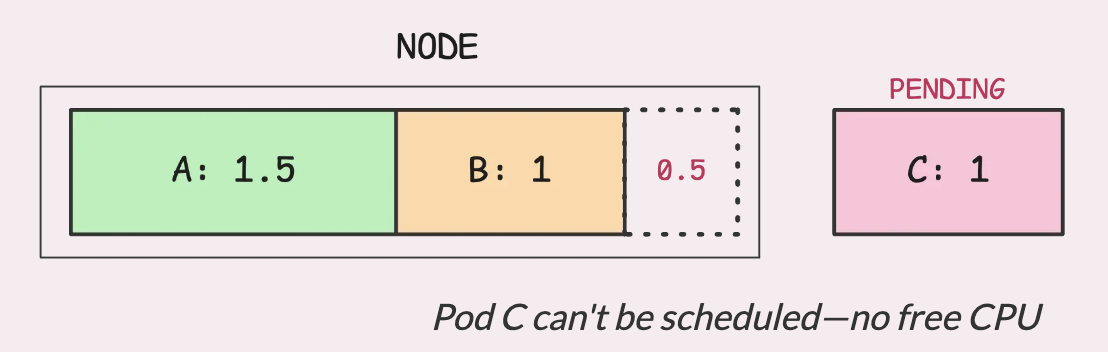
В данном случае на узле можно разместить pod A и B, но не C. Это происходит не потому, что на узле не хватает мощности процессора, а потому, что не осталось свободного(unallocated) запрошенного процессора. Kubernetes резервирует эту мощность, чтобы гарантировать удовлетворение запросов.
2. Поведение среды выполнения во время перегрузки процессора
Запросы CPU становятся особенно важными, когда несколько модулей создают значительную нагрузку на процессор. Ядро все равно будет делить процессор, но оно также гарантирует, что каждый pod получит свою запрошенную долю, даже если другой pod попытается захватить процессор.
Например, предположим, что pod A использует ровно столько ядер процессора, сколько запросил — 1,5 ядра. В то же время pod B испытывает большую нагрузку и стремится получить столько процессорного времени, сколько ему доступно:
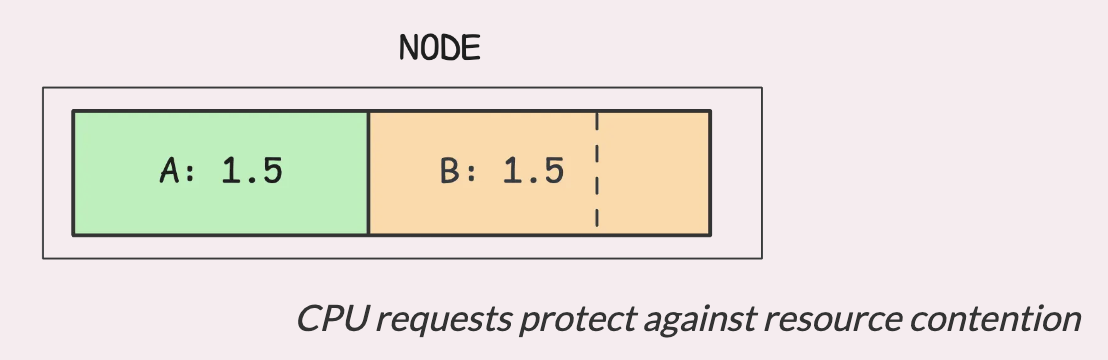
Пока узел не загружен до предела, pod B может использовать любой доступный процессор до своего ограничения, если оно установлено. Однако даже если у него возникнет такая потребность, он не будет мешать pod A получить свою долю ресурсов. Именно в этом заключается смысл запросов на процессор — они задают предел.
Теперь возникает следующий вопрос: что произойдет, если и pod A, и pod B попытаются получить больше CPU, чем им было гарантировано?

В этой борьбе за CPU каждый pod получает процессорное время в соответствии с его запросами.
Поэтому, если Pod A запрашивает 1,5 ядра, а Pod B — только 1 ядро, то вес Pod A будет больше. В таком случае Pod A получит 60% доли процессора, а Pod B — 40% в соответствии с их относительными весами.
Это означает, что если в наличии имеется 0,5 ядра свободного процессора, то A получит 60% от этого количества (0,3 ядра), а B — оставшиеся 40% (0,2 ядра).
Это гарантирует, что даже при высокой нагрузке ресурсы процессора будут распределены справедливым и предсказуемым образом.
CPU Limit
CPU Limit (resources.limits.cpu) используется для ограничения количества процессорного времени, которое может использовать контейнер, даже если у него есть незанятый процессор.
Как только контейнер достигает своего предела, начинается процесс троттлинга (throttling). Это означает, что ядро Linux вынуждает его ждать следующего цикла планирования, прежде чем он сможет получить больше процессорного времени.
Это замедление происходит независимо от общей нагрузки на систему. Поэтому даже если узел не использует процессор, контейнеру всё равно приходится ждать. Для нагрузок, требующих большого количества ресурсов процессора, это может привести к снижению времени отклика или даже к ухудшению производительности.
Один важный момент - CPU limit не влияют на планирование. Контейнер все равно может быть запланирован на узле, даже если общая сумма лимитов CPU для всех контейнеров превышает реальную емкость узла.
На эту тему есть интересный пост Натана Йелина Stop Using CPU Limits on Kubernetes. Основная идея заключается в том, что даже если в Kubernetes не хватает CPU, система всё равно гарантирует вам запрашиваемое количество или справедливую долю. Однако, если вы установите лимит, вы не позволите pod использовать любой свободный процессор, даже если он доступен.
Рассмотрим предыдущий пример. Если pod B ограничен 1 ядром, он не сможет воспользоваться дополнительными 0,5 ядра, которые есть на ноде. Если же pod A не использует все свои 1,5 ядра, Эта неиспользованная часть останется нетронутой. Pod B не сможет воспользоваться ею, даже если она ему понадобится.
Однако использование CPU limit во многом зависит от типа выполняемой задачи. Некоторые приложения действительно полагаются на знание лимита процессора для принятия внутренних решений.
Например, VictororiaMetrics, некоторые приложения на Go и приложения на основе JVM. могут использовать значение лимита CPU для настройки своих внутренних планировщиков или изменения поведения во время выполнения. Это означает, что производительность приложения может зависеть от этого значения.
Если вы не установите CPU limit, контейнер может считать, что у него есть доступ к полной мощности CPU узла.
В экосистеме Go даже есть открытый issue о том, как сделать GOMAXPROCS более осведомленным об ограничениях CFS при работе в Linux: github.com/golang/go/issues/33803
CPU Weight
Как рассчитывается CPU weight
Когда контейнер запускается, он становится обычным процессом в системе Linux. Ядро этой операционной системы использует алгоритм Completely Fair Scheduler (CFS) для определения того, какой процесс будет выполняться следующим и как долго он будет работать. Это решение основывается на взвешенных коэффициентах(weights), а не на фиксированных значениях процессорного времени.
Важно понимать, что resources.requests.cpu в спецификации Kubernetes означает вес. Важен именно относительный вес, а не абсолютный запрос CPU. Другими словами, важно, как запрос процессора контейнера A соотносится с запросом контейнера B.
Например, если у вас есть 2 контейнера, в которых:
- A запрашивает 100m
- B запрашивает 200m
Ядро Linux воспринимает это так же, как если бы A запросил 1 ядро, а B - 2 ядра, или A запросил 3, а B - 6. С точки зрения планировщика, все дело в пропорции.
Соотношение - вот что важно. Если нода загружена, контейнер B в итоге получит в два раза больше процессорного времени, чем контейнер A.
В YAML-файле вашего pod вы можете определить его следующим образом:
resources:
requests:
cpu: "100m" # 0.1 cores
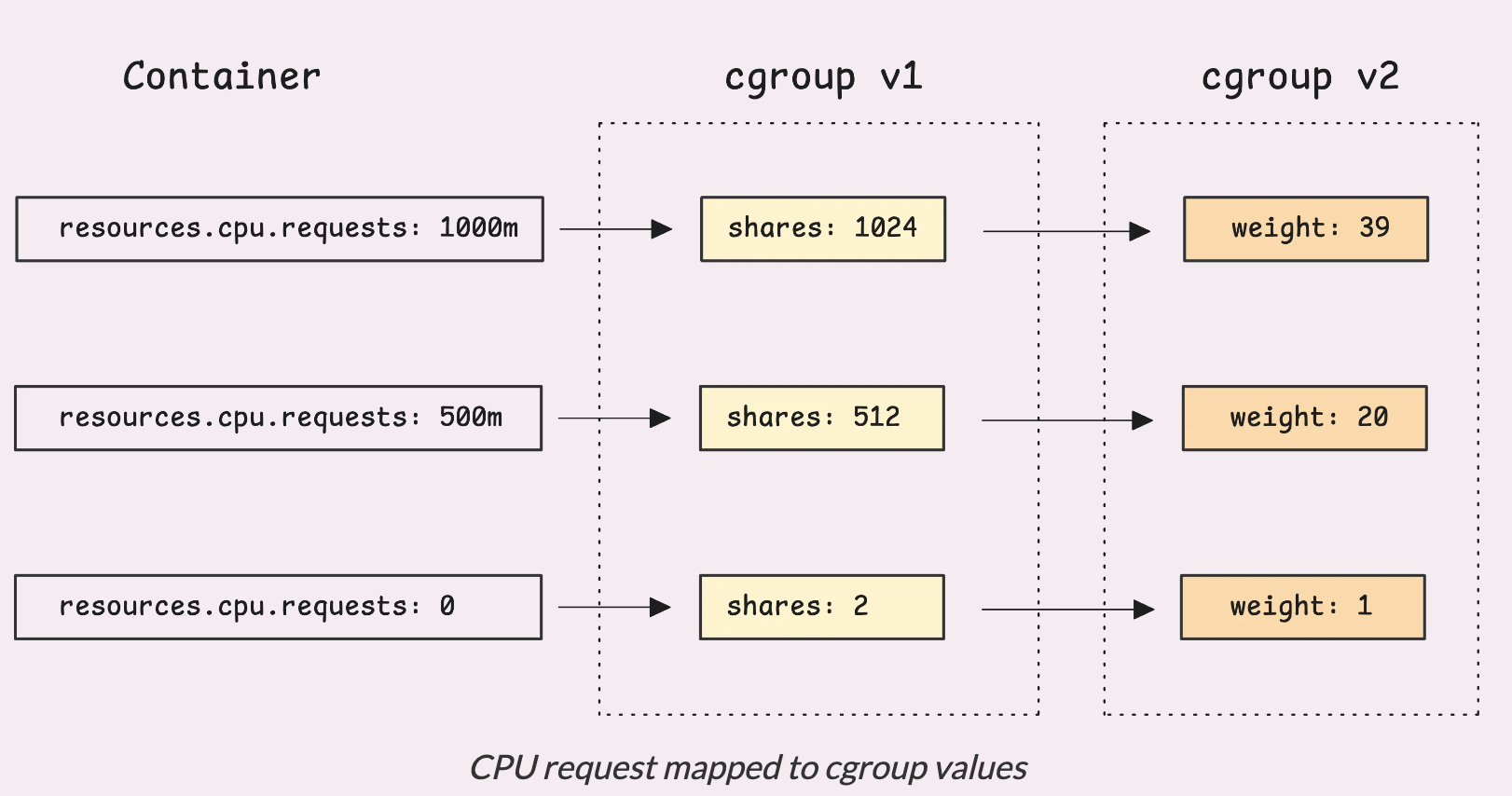
Затем Kubernetes принимает это значение и преобразует его в форму, понятную для Linux. Для cgroup v1 запрос преобразуется в значение cpu.shares. Это число может принимать значения от 2 до 262144 и рассчитывается по следующей формуле:
cgroup_v1.shares = (milliCPU * 1024) / 1000
cgroup_v1.shares = clamp(cgroup_v1.shares, 2, 262144)
Таким образом, если вы не укажете запрос на CPU или установите его значение 0m, Kubernetes предоставит контейнеру минимум 2 доли. С другой стороны, максимальное значение, который можно представить таким образом, составляет 256 ядер (256000m), после чего он просто достигнет своего максимума.
Затем это значение shares преобразуется в cpu.weight для cgroup v2:
cgroup_v2.weight = (((cgroup_v1.shares - 2) * 9999) / 262142) + 1
cgroup_v2.weight = clamp(cgroup_v2.weight, 1, 10000)
Это сопоставляет диапазон shares cgroup v1 (2-262144) с weights cgroup v2 (1-10000).
Во время выполнения weight имеет значение только в контексте конкуренции за процессор. Если ваш контейнер запрашивает 100m, а узел имеет свободные ресурсы, он может получить гораздо больше — возможно, даже одно или два полноценных ядра.
Но когда другие контейнеры начинают конкурировать за CPU, этот weight начинает действовать. Планировщик Linux использует его, чтобы решить, как справедливо разделить процессорное время.
Если конкуренции нет, единственная выполняемая задача просто получит полный доступ к процессору, независимо от ее weight.
Первоначально Kubernetes был создан на основе cgroup v1, которая применяла такие параметры, как cpu.shares. Позже появилась cgroup v2, которая стала стандартным инструментом в последних версиях Linux. Сейчас Kubernetes поддерживает обе версии cgroup и может переключаться между ними в зависимости от ситуации.
Какой контейнер получает больше процессорного времени?
Вес указывает планировщику, сколько процессорного времени должен получить данный контейнер по сравнению с другими. Например, если один контейнер имеет вес 1024, а другой — 2048, ожидается, что второй получит примерно в два раза больше процессорного времени, когда оба будут заняты.
Чтобы обеспечить справедливое распределение ресурсов, планировщик использует так называемое виртуальное время. Каждый поток ведет учет своего собственного виртуального времени (vruntime), которое представляет собой скорректированное количество процессорного времени, которое он получил, с поправкой на его вес.
Планировщик обычно выбирает процесс с наименьшим vruntime для запуска в следующий раз. Это даёт возможность потокам, которые не успели использовать много процессорного времени, наверстать упущенное.
vruntime увеличивается с разной скоростью в зависимости от веса задачи (или потока):
vruntime += actual_runtime * (default_weight / task_weight)
Если поток имеет больший вес (task_weight), его vruntime будет увеличиваться медленнее. Это создаёт впечатление, что он ожидает дольше, увеличивая его шансы быть выбранным для выполнения.
Вот как это работает:
- Если ваш поток имеет вес по умолчанию (
1024), виртуальное время движется с той же скоростью, что и реальное. - Если вес потока больше, например,
2048,vruntimeувеличивается медленнее. - Если же вес потока меньше, например,
512, он быстрее продвигается в виртуальном времени и получает меньше ресурсов процессора во время конкурентной борьбы.
Давайте рассмотрим эту ситуацию на примере. Допустим, у вас есть два потока:
- Thread A с весом
1024 - Thread B с весом
2048
Оба загружены работой и хотят получить как можно больше CPU.
- Если A выполняется в течение
10ms, егоvruntimeувеличивается на10ms * (1024 / 1024) = 10ms - Если B работает в течение
10ms, егоvruntimeувеличивается на10ms * (1024 / 2048) = 5ms.
Таким образом, vruntime B остаётся низким, и планировщик считает, что B всё ещё не получил свою долю работы. Поэтому он продолжает давать B больше возможностей для выполнения задач. Так работает «fairness»: вы получаете процессорное время пропорционально своему весу.
Если поток не нуждается в процессоре в данный момент — возможно, он спит или ожидает ввода-вывода, — его просто исключают из очереди на выполнение.
Когда он просыпается, ему назначают новый vruntime, который соответствует текущему состоянию системы. Благодаря этому он не сильно отстаёт от остальных и может догнать их.
В итоге вес имеет значение только при наличии конкуренции. Если никто больше не просит процессор, ваш контейнер может использовать столько, сколько хочет, даже при малом весе.
CPU Max
CPU max отличается от CPU weight. Веса применяются только тогда, когда есть конкуренция за CPU, а CPU max действует всегда, независимо от того, сколько свободных процессоров в системе.
Когда вы задаете CPU limit в спецификации pod, например 500m, Kubernetes превращает его в значение cpu.max, которое выглядит следующим образом: 50000 100000. Эти два числа представляют собой квоту и период, оба в микросекундах.
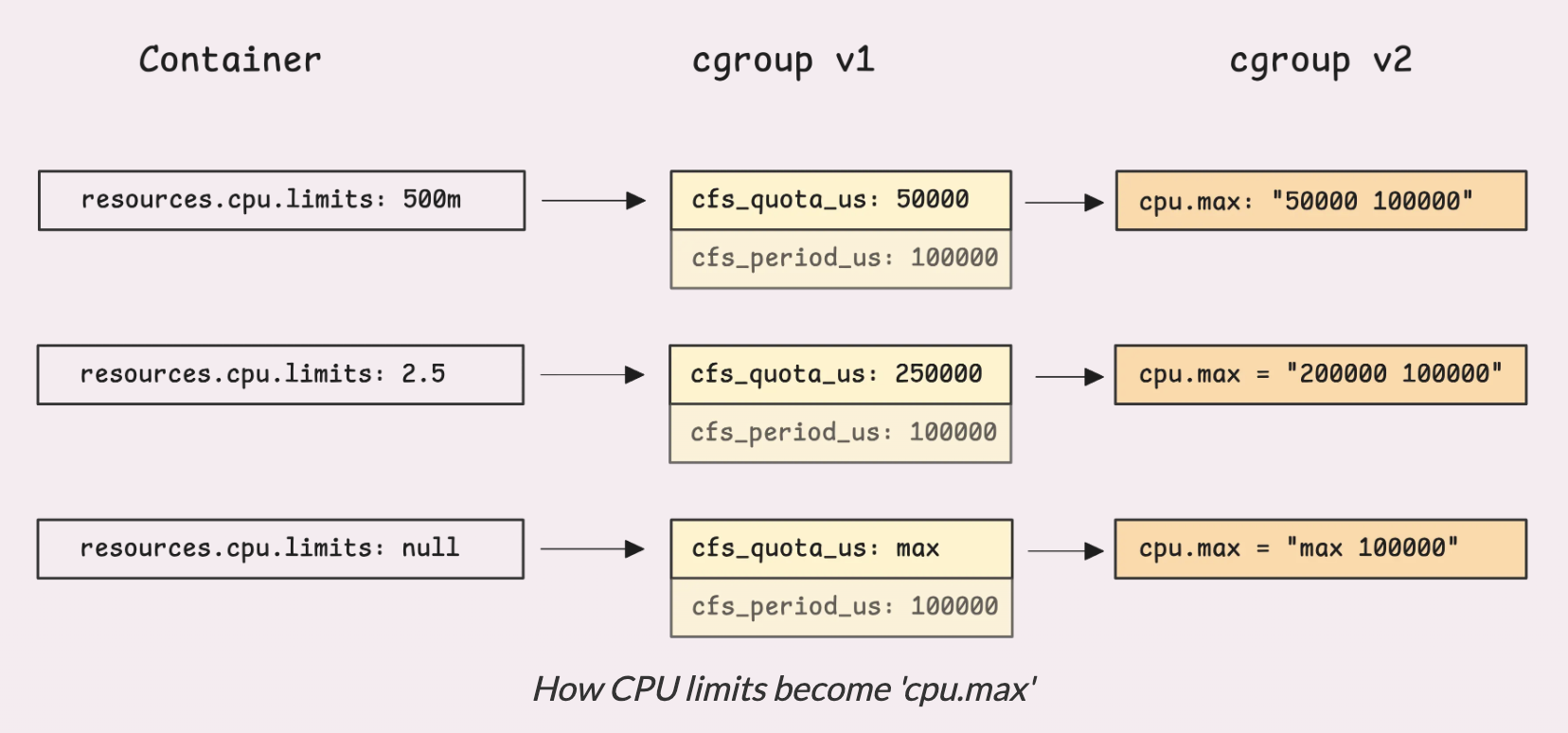
При такой настройке контейнер может использовать только 50% одного ядра за каждые 100ms.
Вот как выглядит расчет:
cgroups_v1.cpu_quota = cores * period
// request = 500m
// -> quota = 0.5 * 100000 = 50ms
Почему период составляет 100 мс?
Kubernetes использует период процессора в 100000 микросекунд (100ms) для настройки квот на процессор в Linux cgroups. Это значение определено как константа в коде Kubernetes:
// 100000 microseconds is equivalent to 100ms
QuotaPeriod = 100000
Это значение 100ms соответствует значению по умолчанию, используемому самим ядром Linux:
/*
* default period for cfs group bandwidth.
* default: 0.1s, units: nanoseconds
*/
static inline u64 default_cfs_period(void)
{
return 100000000ULL;
}
Если у вашего контейнера есть небольшая квота, например, 10ms, он может использовать только это количество процессорного времени в течение периода в 100ms. Если эта квота исчерпана раньше, ядро переводит контейнер в режим ожидания и не назначает его снова до начала следующего периода. В начале каждого нового периода квота обнуляется.
Важно отметить, что если для контейнера не задан лимит процессора, он может использовать всё доступное процессорное время на ноде. Однако, в условиях высокой нагрузки на CPU, фактическое количество времени, которое он получит, будет зависеть от его потребности в процессорном времени по сравнению с другими контейнерами.
А что, если CPU limit составляет, например, 2,5 ядра? Это означает, что значение cpu.max равно 250000 100000. Таким образом, контейнеру предоставляется возможность использовать 250ms процессорного времени каждые 100ms.

На первый взгляд, это может показаться удивительным: почему квота больше, чем период?
Лимит не привязан только к одному процессору. Квота — это общее количество процессорного времени на всех ядрах. Поэтому, если указано 250ms, это означает, что контейнер может использовать такое количество времени на любом количестве доступных ядер.
Например, если на узле установлено четыре ядра и контейнер запускает четыре активных потока, он будет использовать 4ms процессорного времени на каждую 1ms реального времени. В таком случае, чтобы достичь квоты в 250ms, потребуется 62.5ms реального времени(wall time).
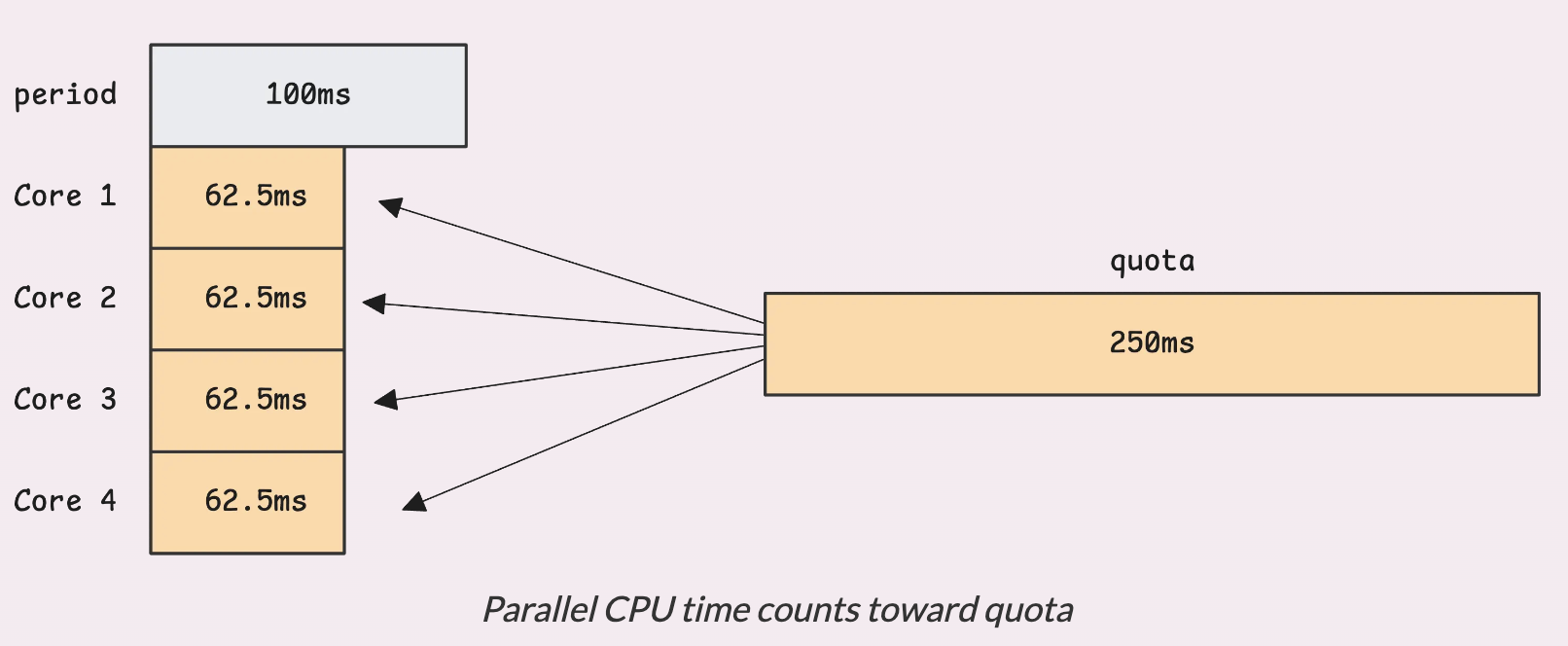
4 cores × 62.5ms = 250ms. Несмотря на то, что время движется вперед со скоростью 1ms в миллисекунду, контейнер использует 4ms процессорного времени каждую миллисекунду. Как только он достигает этого предела, его работа останавливается.
GOMAXPROCS
В Go есть функция runtime.NumCPU(), которая возвращает количество логических CPU, доступных текущему процессу. Это число определяется операционной системой.
С другой стороны, функция runtime.GOMAXPROCS(-1) возвращает текущее максимальное количество процессоров, которые могут работать одновременно. В документации сказано, что GOMAXPROCS «defaults to the value of runtime.NumCPU».
В результате среда выполнения Go по умолчанию устанавливает GOMAXPROCS в соответствии с количеством ядер процессора на машине:
func main() {
fmt.Println(runtime.NumCPU())
fmt.Println(runtime.GOMAXPROCS(-1))
}
// Output:
// 8
// 8
В Kubernetes это общее количество ядер на узле, а не количество ядер, доступных для конкретного контейнера.
Что произойдёт, если ваш контейнер настроен на использование только одного ядра процессора, но при этом работает на узле с 8 ядрами? В таком случае возникнет ситуация, когда у вас будет несоответствие между возможностями и ограничениями.
Может показаться, что использование всех 8 ядер даст лучший результат, ведь так можно достичь большего параллелизма в работе. Однако это не всегда так.
Среда выполнения Go видит 8 ядер и запускает 8 логических процессоров для их соответствия. Но у вашего контейнера есть бюджет только на 100ms процессорного времени каждые 100ms из-за ограничения в 1 ядро.
Теперь представьте, что среда выполнения планирует все 8 потоков одновременно, и все они выполняют задачи, связанные с процессором. Контейнер распределяет своё процессорное время между всеми 8 ядрами, работая параллельно. В результате 8 потоков используют 100ms всего за 12.5ms реального времени (8 × 12.5ms = 100ms).
Как только контейнер достигает предела в 100ms, ядро Linux прекращает его работу. Все потоки останавливаются до следующего периода. Это может произойти очень быстро.
Однако, если вы установите GOMAXPROCS=1, среда выполнения Go будет запускать только один поток за раз. В таком случае этот поток сможет использовать все 100ms без досрочного превышения квоты.
Означает ли это, что поток всегда работает на одном и том же ядре?
Вовсе нет. Даже при GOMAXPROCS=1 поток может работать на любом ядре. Он просто не будет работать на нескольких ядрах одновременно.
Ядро Linux может свободно перемещать его между процессорами в зависимости от нагрузки, мощности или кэша. Но одновременно код Go выполняется только в одном потоке.
Вот несколько веских аргументов в пользу установки GOMAXPROCS=1 в таких настройках:
- Планировщик Linux стремится минимизировать перемещение потоков между ядрами, если в этом нет реальной необходимости. Такое перемещение требует дополнительных затрат, поэтому обычно потоки остаются на одном ядре после запуска.
- Переключение между потоками операционной системы может быть довольно затратным процессом. Однако, в среде Go переключение между горутинами происходит очень быстро. Планировщик Go способен приостанавливать выполнение одной горутины и запускать другую с минимальными накладными расходами — при условии, что все операции выполняются в рамках одного потока.
- Если несколько потоков будут замедляться(throttled) в разное время, это может негативно сказаться на сборке мусора.
Третий вариант стоит рассмотреть подробнее.
Допустим, ваше приложение Go использует 8 потоков ОС, с GOMAXPROCS=8. В какой-то момент начинается сборка мусора, и нужно ненадолго сделать stop the world - поставить на паузу все горутины. Для этого каждый поток, управляемый Go, должен достичь безопасной точки и подтвердить свою готовность.
Но если один из этих потоков в данный момент замедляться(throttled) ядром Linux - потому что вы уже превысили квоту CPU, - то он не может ответить на сигнал GC. Это задерживает весь процесс. Приложению приходится ждать, пока этот поток снова получит процессорное время, прежде чем GC сможет завершиться.
Это одна из скрытых проблем, которая возникает, когда контейнеры имеют избыточное резервирование потоков, но не достаточно — процессорного времени.
Как установить GOMAXPROCS?
Расмотрим библиотеку uber-go/automaxprocs.
import _ "go.uber.org/automaxprocs"
- Если вы уже задали
GOMAXPROCSвручную, он оставит его в покое и будет использовать этот параметр. - В Linux он проверяет лимиты CPU, используя значения cgroup. Он поддерживает cgroup v1 и v2:
- Для cgroup v1, читает из
cpu.cfs_quota_usиcpu.cfs_period_us - Для cgroup v2, читает из
cpu.max
- Для cgroup v1, читает из
- Делит квоту на период (
quota / period), чтобы определить, сколько логических процессоров доступно. - Округление происходит до ближайшего целого числа, с точностью до 1.
- Таким образом, квота в 2,7 процессора становится
GOMAXPROCS=2.
- Таким образом, квота в 2,7 процессора становится
- Наконец, он устанавливает
GOMAXPROCSна вычисленное число.
Этот пакет создан специально для Linux - он ничего не сделает на таких платформах, как macOS, Windows или FreeBSD.
Откуда он читает
cpu.cfs_quota_us,cpu.cfs_period_usилиcpu.max?
В начале статьи мы рассмотрели путь /sys/fs/cgroup, который является локальным для узла и позволяет найти все необходимые данные. Этот путь можно увидеть как на самом узле, так и внутри контейнера.
Когда контейнер читает из /sys/fs/cgroup, он видит версию дерева cgroup, предназначенную только для его собственной cgroup. Вы можете проверить это самостоятельно:
$ cat /sys/fs/cgroup/cpu.max
max 100000
Под капотом среда выполнения контейнера устанавливает новое mount namespace, которое включает монтирование procfs в /proc.
Именно здесь uber-go/automaxprocs делает большую часть своей работы. Он использует два ключевых файла:
/proc/self/cgroupсообщает, в какой cgroup входит текущий процесс. В cgroup v2 это обычно что-то вроде0::/./proc/self/mountinfoдает подробную информацию о том, куда смонтирована cgroup2 - обычно это/sys/fs/cgroup.
Библиотека считывает эти файлы, чтобы найти путь к cgroup и место, где смонтирована файловая система cgroup. Затем она извлекает данные о квоте и периоде, чтобы рассчитать доступное процессорное время.
Метрики
Все основные показатели CPU и throttling поступают от cAdvisor, который работает как часть kubelet.
CPU Stats
Большая часть отчетов cAdvisor берется прямо из файлов типа /sys/fs/cgroup/.../cpu.stat.
$ cat /sys/fs/cgroup/cpu.stat
usage_usec 2618589
user_usec 2102728
system_usec 515861
nr_periods 309
nr_throttled 164
throttled_usec 15383840
nr_bursts 0
burst_usec 0
Вот как эти значения соотносятся с теми показателями, которые вы обычно видите:
container_cpu_usage_seconds_total- это общее процессорное время, используемое всеми ядрами вашего контейнера. Оно берется из поляusage_usecв файлеcpu.stat.container_cpu_user_seconds_totalиcontainer_cpu_system_seconds_totalотслеживают время, проведенное в пользовательском режиме и режиме ядра, взятое изuser_usecиsystem_usec.container_cpu_cfs_periods_totalпоказывает, сколько 100ms CPU windows прошло. Получено изnr_periods.container_cpu_cfs_throttled_periods_totalпоказывает, сколько раз контейнер замедляться(throttled) в течение всех периодов. Например, если ваш контейнер был ограничен в30из50окон, то это значение будет равно30. Оно коррелирует сnr_throttled.container_cpu_cfs_throttled_seconds_totalпоказывает, сколько общего времени контейнер замедлялся(throttled). Если он был приостановлен на30msв каждом из10периодов, это покажет 300000 (300ms). Это следует изthrottled_usec.
Если в контейнере не установлен CPU-лимит, то все поля, начиная с nr_periods и ниже, обычно равны нулю. Отсутствие лимита означает отсутствие троттлинга(throttled).
Если вы сталкиваетесь с высоким уровнем троттлинга, например, более 10%, это обычно указывает на то, что CPU-лимит не соответствует потребностям вашего контейнера. Вы можете не заметить это, просто взглянув на среднее использование процессора, но последствия для производительности будут очевидны.
Сразу предупреждаем, что cAdvisor не отслеживает nr_bursts или burst_usec. Эти два поля связаны с функцией burst в CFS.
Они отображают, сколько раз контейнер выходил за пределы своей стандартной квоты, используя все сэкономленное процессорное время, накопленное за предыдущие периоды.
Например, если ваш контейнер обычно получает 50ms каждые 100ms, и у него есть 20ms на burst, он может использовать 60ms в период высокой нагрузки. Это будет считаться одним burst.
CPU Pressure
cAdvisor также получает данные о CPU Pressure с помощью файла cpu.pressure.
Этот файл создан системой PSI (Pressure Stall Information) Linux, которая отслеживает, когда задачи задерживаются или останавливаются из-за нехватки ресурсов - когда процессор слишком занят, чтобы справиться со всем сразу.
$ cat /sys/fs/cgroup/cpu.pressure
some avg10=12.02 avg60=15.07 avg300=14.00 total=87546620
full avg10=12.02 avg60=15.06 avg300=13.98 total=87399907
some- это время, когда хотя бы одна задача в вашем контейнере хотела получить CPU, но вынуждена была ждать. Это признак нехватки CPU, но работа все равно идет, просто с небольшой задержкой.full- более значимый. Это когда каждая выполняемая задача в контейнере останавливается. В это время ничего не работало.- Значения
avg10,avg60,avg300показывают экспоненциально взвешенные скользящие средние за 10, 60 и 300 секунд. Так,avg10=4,23означает, что за последние 10 секунд задачи останавливались примерно на 4,23% времени. total- это сумма всего времени (в микросекундах), в течение которого задания были остановлены с момента запуска PSI.
На основе этих данных cAdvisor рассчитывает несколько показателей:
container_pressure_cpu_stalled_seconds_total: общее время, в течение которого все задачи в контейнере были остановлены. Это значение берется изfull.total.container_pressure_cpu_waiting_seconds_total: общее время, в течение которого хотя бы некоторые задачи были остановлены. Получено изsome.total.
Эти две метрики дают вам непосредственное представление о том, насколько сильно загружен процессор в ваших контейнерах - то, что не всегда хорошо видно по необработанным показателям CPU.
Комментарии в Telegram-группе!