
- Transactional Outbox. Как не потерять сообщения
- Two-Phased Commit и eXtended Architecture
- SAGA. Распределенные транзакции
- Try-Confirm-Cancel в распределенных системах
Переход от монолитов к распределённым микросервисам сделал системы более гибкими и масштабируемыми, но усложнил поддержание привычной целостности данных. В монолите транзакции обеспечивались ACID (Atomicity, Consistency, Isolation, Durability) в единой БД, а в микросервисной архитектуре каждый сервис владеет своей базой — классические распределённые механизмы вроде двухфазная фиксация (2PC) здесь либо непрактичны, либо невозможны.
Паттерн SAGA опирается на конечной согласованности (eventual consistency): последовательность локальных транзакций и, при необходимости, компенсирующих шагов гарантирует, что система в итоге придёт в корректное состояние, перекладывая ответственность за согласованность на прикладную логику.
Сравнение транзакционных моделей
| Характеристика | ACID (Локальная транзакция) | 2PC (Двухфазная фиксация) | Saga (Сага) |
|---|---|---|---|
| Тип согласованности | Строгая (Strong) | Строгая (Strong) | Конечная (Eventual) |
| Изоляция | Высокая (Блокировки БД) | Высокая (Распределенные блокировки) | Отсутствует (Требует контрмер) |
| Доступность | Высокая в рамках узла | Низкая (Зависимость от всех узлов) | Высокая (Асинхронность) |
| Масштабируемость | Ограничена одним узлом | Плохая (Длительные блокировки) | Отличная |
| Механизм отката | Автоматический (Rollback) | Координированный откат | Компенсирующие транзакции |
Теоретические основы и структура паттерна Saga
Концепция Saga была сформулирована в научной среде в конце 1980-х годов и предназначалась для координации длительных транзакций. В контексте микросервисов Saga определяется как последовательность локальных транзакций T_1, T_2, T_n. Каждая локальная транзакция T_i обновляет базу данных внутри одного сервиса и инициирует выполнение следующего шага через событие или сообщение.
Если рассматривать Saga формально, то для каждой транзакции T_i, которая может завершиться неудачей, должна существовать соответствующая компенсирующая транзакция C_i. Компенсирующая транзакция семантически отменяет изменения, внесенные T_i.
Успешное выполнение Saga выглядит как последовательность:
S = {T_1, T_2, T_3, ..., T_n}
В случае сбоя на шаге k, Saga инициирует последовательность компенсаций в обратном порядке:
S = {T_1, T_2, ..., T_k, C_k-1, ..., C_2, C_1}
Важно понимать, что компенсация — это не физический откат (rollback) на уровне БД. Поскольку T_i уже зафиксирована в локальном хранилище, C_i — это новая транзакция, которая вносит корректирующие изменения, например, вместо удаления записи о платеже она может создать запись о возврате средств.
Пример Saga: создание заказа
Первая локальная транзакция инициируется внешним запросом создания заказа. Остальные пять транзакций срабатывают одна за другой.
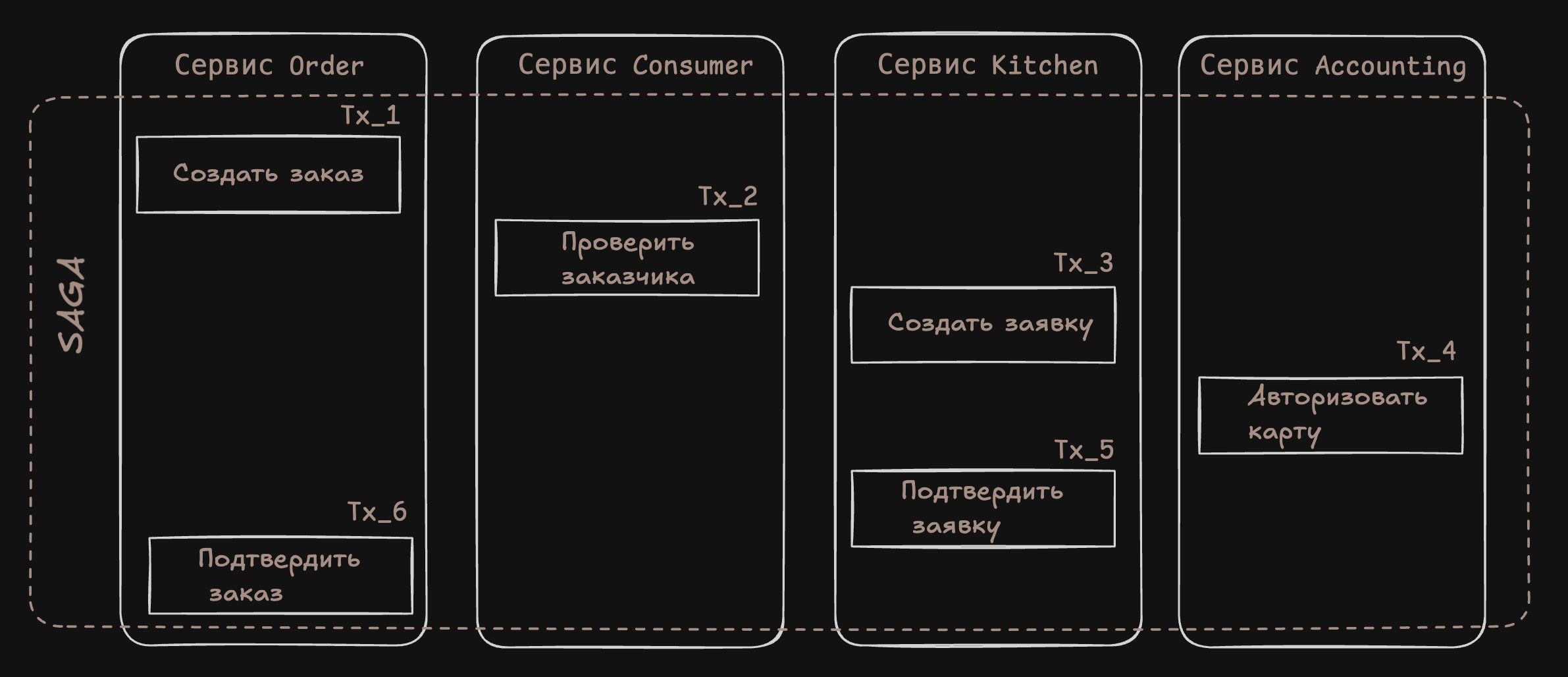
Это Saga состоит из следующих локальных транзакций.
- Сервис Order. Создает заказ с состоянием
APPROVAL-PENDING. - Сервис Consumer. Проверяет, может ли заказчик размещать заказы.
- Сервис Kitchen. Проверяет детали заказа и создает заявку с состоянием
CREATE-PENDING. - Сервис Accounting. Авторизует банковскую карту заказчика.
- Сервис Kitchen. Меняет состояние заявки на
AWAITING_ACCEPTANCE. - Сервис Order. Меняет состояние заказа на
APPROVED.
Классификация транзакций в составе Saga
Для проектирования надежных распределенных процессов архитекторы разделяют транзакции внутри Saga на три ключевые категории, каждая из которых имеет свои требования к надежности и возможности отката.
Компенсируемые транзакции (Compensable Transactions)
Это транзакции, которые могут быть отменены. Они составляют первую часть Saga. Если какой-либо последующий шаг завершается ошибкой, для каждой успешно завершенной компенсируемой транзакции вызывается её “антипод” — компенсирующая транзакция. Проектирование таких операций требует учета того, что данные уже могли быть считаны другими процессами, что вводит понятие отсутствия изоляции.
Поворотная транзакция (Pivot Transaction)
Поворотная транзакция — это точка невозврата в выполнении Saga. Если эта транзакция завершается успешно, считается, что Saga будет доведена до конца в любом случае. Поворотная транзакция может не иметь компенсирующей транзакции. Часто она является либо последней компенсируемой операцией, либо первой повторяемой операцией в цепочке. Пример: окончательное списание средств с баланса после всех проверок. Если деньги списаны, процесс доставки товара должен быть завершен обязательно.
Повторяемые транзакции (Retryable Transactions)
Это операции, следующие за поворотной транзакцией. Они характеризуются тем, что не могут завершиться окончательной ошибкой. Если происходит технический сбой (например, сетевая недоступность), система должна повторять эти транзакции до тех пор, пока они не будут успешно выполнены. Следовательно, эти транзакции должны быть строго идемпотентными, чтобы многократное выполнение не привело к некорректным результатам.
| Тип транзакции | Допустимость сбоя | Необходимость компенсации | Гарантия успеха |
|---|---|---|---|
| Компенсируемая | Да | Да | Нет |
| Поворотная | Критическая точка | Нет (обычно) | Определяет исход |
| Повторяемая | Нет (только временные сбои) | Нет | Да (через повторы) |

Координация Saga: Архитектурные стратегии
Выбор механизма координации определяет, как сервисы будут взаимодействовать друг с другом для продвижения по шагам Saga. Существует два доминирующих подхода: хореография и оркестрация.
Децентрализованная хореография (Choreography)
В модели хореографии управление распределено между всеми участниками. Нет центрального контроллера, который бы отдавал команды. Вместо этого сервисы обмениваются событиями через общую шину данных. Каждый сервис “знает”, на какие события ему нужно реагировать, выполняет свою локальную работу и публикует новое событие, сигнализирующее о завершении этапа.
Механизм работы:
- Сервис А выполняет локальную транзакцию и публикует событие
A_Completed. - Сервис Б прослушивает
A_Completed, выполняет свою работу и публикуетB_Completed. - Если Сервис Б сталкивается с ошибкой, он публикует
B_Failed, на которое реагирует Сервис А, запуская свою компенсирующую транзакцию.
Преимущества:
- Слабая связанность: Сервисы не зависят от центрального узла и могут развиваться независимо.
- Отсутствие единой точки отказа: Сбой одного координатора не парализует всю систему.
- Простота реализации для коротких цепочек: Для 2–3 шагов этот подход требует минимум инфраструктуры.
Недостатки:
- Сложность понимания потока: Логика бизнес-процесса “размазана” по коду множества сервисов.
- Риск циклических зависимостей: Сервисы могут начать бесконечно публиковать события друг другу при некорректном дизайне.
- Трудности отладки и мониторинга: Крайне сложно отследить состояние конкретной Saga в реальном времени без специализированных инструментов трассировки.
Централизованная оркестрация (Orchestration)
Оркестрация предполагает выделение специального компонента — оркестратора Saga (Saga Orchestrator), который берет на себя роль диспетчера. Оркестратор хранит состояние Saga и отправляет команды (не события, а именно директивные сообщения) сервисам-участникам.
Механизм работы:
- Оркестратор отправляет команду
Execute_Aв Сервис А. - Сервис А отвечает
A_Success. - Оркестратор фиксирует состояние и отправляет
Execute_Bв Сервис Б. - В случае ответа
B_Failureоркестратор отправляет командуCompensate_Aобратно в Сервис А.
Преимущества:
- Централизованная логика: Весь бизнес-процесс описан в одном месте, что упрощает его изменение и аудит.
- Упрощение сервисов: Микросервисам не нужно знать о других участниках Saga, они просто выполняют команды.
- Легкость обработки ошибок: Оркестратор может легко управлять тайм-аутами, повторными попытками и сложными ветвлениями логики.
Недостатки:
- Единая точка отказа: Если оркестратор недоступен, новые Saga не могут быть начаты.
- Риск перегрузки: Оркестратор может стать “узким местом” производительности при больших нагрузках.
- Усложнение инфраструктуры: Требуется надежное хранилище состояний для самого оркестратора.
| Критерий | Хореография | Оркестрация |
|---|---|---|
| Центр управления | Отсутствует (децентрализовано) | Оркестратор (централизовано) |
| Связанность | Низкая (через события) | Средняя (зависимость от команд) |
| Видимость процесса | Низкая (требует распределенной трассировки) | Высокая (состояние в БД оркестратора) |
| Применимость | Простые рабочие процессы | Сложные корпоративные процессы |
| Управление отказами | Каждый сервис сам решает, как реагировать | Оркестратор координирует все откаты |
Проблема изоляции и аномалии данных
Отказ от распределенных блокировок в Saga означает потерю свойства изоляции (Isolation) из набора ACID. Это приводит к тому, что промежуточные, еще не зафиксированные (или потенциально отменяемые) данные становятся видимыми другим транзакциям. В распределенных системах это порождает ряд аномалий, которые могут критически повлиять на бизнес.
Потерянные обновления (Lost Updates)
Аномалия возникает, когда две Saga одновременно пытаются обновить одну и ту же запись. Первая Saga считывает значение, вторая Saga также считывает его. Затем обе Saga записывают обновленное значение, при этом результат работы одной из них полностью затирается другой.
Пример: Две Saga одновременно пытаются изменить статус заказа. Первая переводит его в “Оплачено”, вторая (параллельная отмена) — в “Отменено”. Если Saga оплаты запишет свой статус последней, отмена будет проигнорирована.
“Грязные” чтения (Dirty Reads)
“Грязное” чтение случается, когда транзакция считывает данные, измененные Saga, которая еще не завершилась и впоследствии может быть отменено.
Пример: Saga создания заказа временно увеличивает кредитный лимит пользователя (ошибочно или как промежуточный этап). В этот момент другая Saga одобряет покупку, видя этот повышенный лимит. Затем первая Saga завершается неудачей и откатывает лимит назад. В итоге пользователь совершил покупку, на которую у него не было реальных средств.
Неповторяющиеся чтения (Non-repeatable Reads)
Проблема возникает, когда один шаг Saga считывает данные, а на следующем шаге (при повторном чтении тех же данных) получает другой результат, так как параллельная Saga успела внести изменения. Это создает неопределенность в логике принятия решений распределенным алгоритмом.
Контрмеры против аномалий отсутствия изоляции
Для минимизации рисков, связанных с отсутствием изоляции, архитекторы применяют набор стратегий, предложенных Ларсом Франком и Торбеном Зале. Эти контрмеры позволяют эмулировать изоляцию на уровне приложения.
Семантическая блокировка (Semantic Lock)
Суть метода заключается во введении прикладных статусов, которые действуют как блокировки. Вместо блокировки на уровне строк БД, сервис помечает запись состоянием PENDING.
- Механизм: Когда Saga начинает изменять объект (например, Заказ), она переводит его в состояние
APPROVAL_PENDING. Все остальные Saga, видя этот статус, “знают”, что объект занят, и либо блокируются, либо возвращают ошибку клиенту. - Завершение: Блокировка снимается либо финальной успешной транзакцией (статус
APPROVED), либо компенсирующей транзакцией (статусREJECTED).
Коммутативные обновления (Commutative Updates)
Операции проектируются таким образом, чтобы порядок их выполнения не влиял на итоговый результат. Это исключает проблему потерянных обновлений.
- Механизм: Вместо установки абсолютного значения (например,
set balance = 100), используются относительные изменения (add 50,subtract 20). - Пример: Операции дебета и кредита по счету коммутативны. Если Saga отменяется, мы просто выполняем обратную операцию. Даже если между дебетом и его компенсацией вклинится другая транзакция, итоговая сумма на счету будет математически верной.
Пессимистический взгляд (Pessimistic View)
Эта стратегия направлена на устранение “грязных” чтений через изменение последовательности шагов Saga.
- Механизм: Шаги Saga переупорядочиваются так, чтобы наиболее рискованные с точки зрения бизнеса обновления (например, окончательное начисление бонусов или возврат средств) происходили в фазе повторяемых транзакций, т.е. после точки невозврата.
- Результат: Другие транзакции не смогут увидеть “сомнительные” данные, так как эти данные записываются только тогда, когда Saga гарантированно не будет откачена.
Перечитывание значения (Reread Value)
Метод предотвращает потерю обновлений через проверку состояния данных непосредственно перед записью.
- Механизм: Перед тем как выполнить обновление, Saga считывает текущую версию записи и сравнивает ее с той, что была в начале шага. Если данные изменились (параллельное вмешательство), шаг прерывается и Saga либо перезапускается, либо откатывается. Это классический паттерн оптимистической блокировки (Optimistic Offline Lock).
Файл версий (Version File)
Метод используется для корректной обработки сообщений, которые могут приходить в неверном порядке в асинхронной среде.
- Механизм: Каждый сервис записывает все операции, произведенные над сущностью, в локальный лог.
- Пример: Если запрос на отмену авторизации банковской карты пришел раньше, чем запрос на саму авторизацию, сервис записывает “отмена для транзакции X”. Когда позже придет запрос на авторизацию, сервис увидит в логе запись об отмене и не будет блокировать средства.
По значению (By Value)
Стратегия управления рисками, при которой выбор между Saga и распределенной транзакцией (2PC) делается на основе стоимости операции.
- Механизм: Для мелких, низкорисковых транзакций (например, начисление очков лояльности) используется Saga, обеспечивающая высокую производительность. Для критических, высокорисковых операций (например, перевод крупных сумм между банками) может быть оправдано использование тяжелых протоколов со строгой изоляцией.
| Контрмера | Решаемая аномалия | Принцип действия |
|---|---|---|
| Семантическая блокировка | Потерянные обновления, Грязные чтения | Прикладные статусы (PENDING) |
| Коммутативные обновления | Потерянные обновления | Использование относительных изменений |
| Пессимистический взгляд | Грязные чтения | Перенос рискованных шагов в конец |
| Перечитывание значения | Потерянные обновления | Оптимистическая проверка перед записью |
| Файл версий | Неверный порядок операций | Логирование всех входящих команд |
| По значению | Все типы (через выбор модели) | Оценка бизнес-риска транзакции |
Проектирование распределенной Saga
Проектирование Saga — это не только техническая, но и аналитическая задача. Она требует декомпозиции бизнес-процесса на атомарные шаги, каждый из которых должен обладать определенными свойствами.
Шаг 1: Идентификация границ транзакций
На первом этапе необходимо определить, какие действия должны выполняться в рамках одного сервиса (локальные транзакции), а какие требуют межсервисного взаимодействия. Идеальная Saga минимизирует количество распределенных шагов, объединяя тесно связанные данные в один сервис.
Шаг 2: Проектирование компенсирующих действий
Для каждого действия, которое может потребовать отката, должна быть создана компенсирующая транзакция.
- Требование: Компенсация не может завершиться ошибкой. Если она не удалась из-за технических причин, система должна повторять её до успеха.
- Семантика: Компенсация должна учитывать бизнес-контекст. Например, если товар был забронирован, компенсацией будет снятие брони. Если письмо было отправлено — компенсацией может быть отправка второго письма с исправлением.
Шаг 3: Обеспечение идемпотентности
Поскольку Saga полагаются на асинхронные сообщения и повторные попытки (retries), каждый участник Saga должен уметь обрабатывать одно и то же сообщение несколько раз без негативных последствий. Это достигается через:
- Сохранение идентификаторов обработанных сообщений в базе данных.
- Проверку статуса объекта перед выполнением операции (если заказ уже оплачен, повторный сигнал об оплате игнорируется).
Шаг 4: Надежный обмен сообщениями
Сбой может произойти между фиксацией локальной транзакции в БД и отправкой сообщения в брокер (например, RabbitMQ или Kafka). Для решения этой проблемы используется паттерн Transactional Outbox.
- В рамках одной транзакции БД сервис обновляет бизнес-сущность и записывает сообщение в специальную таблицу
outbox. - Отдельный процесс (Message Relay) считывает записи из
outboxи пересылает их в брокер. - Это гарантирует, что сообщение будет отправлено “хотя бы один раз” (at-least-once).
Шаг 5: Использование Correlation ID
Для того чтобы разные сервисы могли соотнести события с одной и той же Saga, каждое сообщение должно содержать уникальный идентификатор корреляции (Correlation ID).Это позволяет оркестратору или участникам хореографии извлекать правильное состояние из своих баз данных при получении асинхронного ответа.
Мониторинг и Observability
Распределенные транзакции крайне сложны в эксплуатации. Когда процесс “зависает” где-то между пятью сервисами, администраторам необходимы инструменты для диагностики.
Распределенная трассировка
Системы трассировки позволяют визуализировать граф вызовов Saga. Каждому шагу присваивается TraceID, который передается вместе с сообщениями. Это позволяет увидеть задержки на каждом этапе и идентифицировать сервис, ставший причиной сбоя.
Журнал состояний (Saga Log)
В оркестрации журнал состояний ведется самим оркестратором. В хореографии рекомендуется использовать специализированные сервисы сбора событий, которые агрегируют сообщения от разных участников и строят общую картину выполнения процесса. Это критично для понимания того, на какой стадии находится бизнес-транзакция (например, “деньги списаны, но товар еще не забронирован”).
Тайм-ауты и Dead Letter Queues (DLQ)
Если сервис-участник не отвечает в течение заданного времени, Saga должна принять решение: либо повторить попытку, либо начать процесс компенсации. Необработанные сообщения, вызвавшие критические ошибки, должны перемещаться в очереди недоставленных сообщений (DLQ) для ручного анализа инженерами, чтобы предотвратить потерю данных.
Сравнение Saga с альтернативными паттернами
Паттерн Saga — не единственный способ управления консистентностью.
- Saga vs TCC: В TCC сервис сначала резервирует ресурсы (Try), а затем либо подтверждает их использование (Confirm), либо освобождает (Cancel). TCC обеспечивает более высокую степень изоляции, чем Saga, но требует, чтобы все участники поддерживали двухфазный интерфейс, что сложнее в реализации.
- Saga vs 2PC: Как уже отмечалось, 2PC — это синхронный протокол со строгой согласованностью, тогда как Saga — асинхронный протокол с конечной согласованностью. Выбор между ними часто сводится к выбору между согласованностью и доступностью согласно CAP-теореме.
Заключение
Saga — это архитектурный компромисс: она отходит от немедленной согласованности в пользу доступности и масштабируемости, возлагая ответственность за корректность бизнес-логики на прикладной уровень. Успешная реализация требует грамотной декомпозиции процесса, идемпотентных операций, надёжной доставки сообщений и продуманного мониторинга. Там, где риск бизнес-несогласованности недопустим, следует предпочесть модели с более жёсткой изоляцией; в большинстве же облачных систем Saga остаётся практичным и гибким решением для сложных распределённых процессов.
Комментарии в Telegram-группе!