Перевод The Return of the Frame Pointers
Иногда отладчики и профилировщики явно сломаны, иногда это незаметно и трудно обнаружить. Со страницы flame graphs:

Это довольно частое явление, которое обычно остается незамеченным, поскольку на первый взгляд flame graph выглядит нормально. Но 15% сэмплов слева, над «[unknown]», находятся в неправильном месте и лишены кадров. Проблема в том, что в этой системе по умолчанию используется libc, скомпилированная без frame pointers, поэтому любое перемещение по стеку останавливается на уровне libc, создавая неполный стек, в котором отсутствуют application frames. Эти частичные стеки группируются слева.
Чтобы объяснить этот пример более подробно: Профилировщик периодически прерывает выполнение программ, и для этих отключенных стеков это оказывается выполнение программ ядра («vfs*», «ext*» и т.д.). После прерывания профилировщик начинает с верхнего края flame graph (или нижнего, если вы используете схему icicle) и затем «пробирается» вниз по прямоугольникам, чтобы собрать трассировку стека. В конце концов он проходит через кадры ядра, затем через системный вызов (sys_write()) в пользовательское пространство, попадает в обертку системного вызова libc (__GI___libc_write()), затем пытается определить символ для следующего кадра, но терпит неудачу и записывает «[unknown]». Это происходит из-за оптимизации компилятора, когда регистр frame pointer используется для хранения данных вместо frame pointer, но это просто число, поэтому профилировщик не знает об этом и пытается сопоставить этот адрес с символом функции и терпит неудачу (поэтому он является неизвестным символом). Затем профилировщик обычно не может пройти больше кадров, потому что эти данные не указывают на следующий кадр (и, скорее всего, не указывают на какое-либо корректное сопоставление, потому что для профилировщика это фактически случайное число), поэтому он останавливается, не дойдя до application frames. Вероятно, в левой отсоединенной “башне” не хватает нескольких кадров, похожих на кадры приложений, которые вы видите справа (этот пример - оболочка bash(1)). Что произойдет, если случайные данные по совпадению окажутся правильным указателем? Обычно вы получаете дополнительный кадр мусора. Я видел ситуации, когда случайные данные в конечном итоге указывают сами на себя, так что профилировщик зацикливается, и вы получаете башню из нежелательных кадров, пока perf не достигнет своего лимита.
Другие типы профилирования сталкиваются с этим чаще. Off-CPU flame graphs, например, могут доминировать функции libc для чтения/записи и мьютексы, поэтому без фрейм-указателей они оказываются в основном нерабочими. Кроме библиотечного кода, возможно, в вашем приложении также нет frame pointers, и в этом случае все сломано.
Я пишу об этой проблеме сейчас, потому что Fedora и Ubuntu выпускают версии, которые исправляют это, компилируя libc и многое другое с frame pointers по умолчанию. Это отличная новость, поскольку она не только исправляет эти flame graphs, но и делает off-CPU flame graphs гораздо более применимыми. Это также победа для continuous profilers (мой работодатель, Intel, только что анонсировал один из них), так как это облегчает внедрение у клиентов.
Что такое frame pointers?
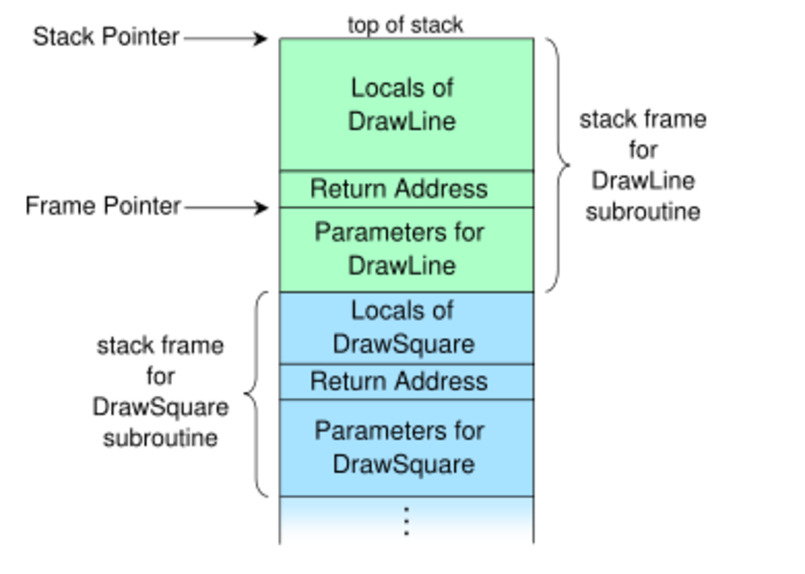
В x86-64 ABI документация показано, как регистр процессора, %rbp, может быть использован как “base pointer” на стек фрейме, как “frame pointer.”
Stack Frame with Base Pointer
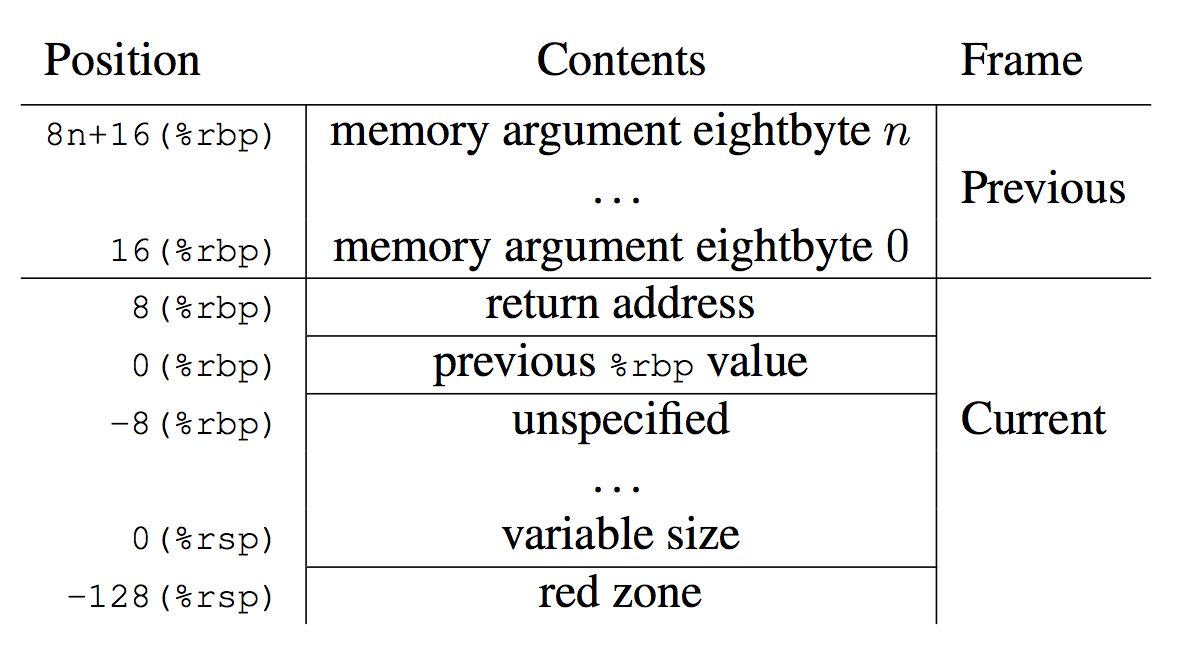
Frame Pointer-based Stack Walking
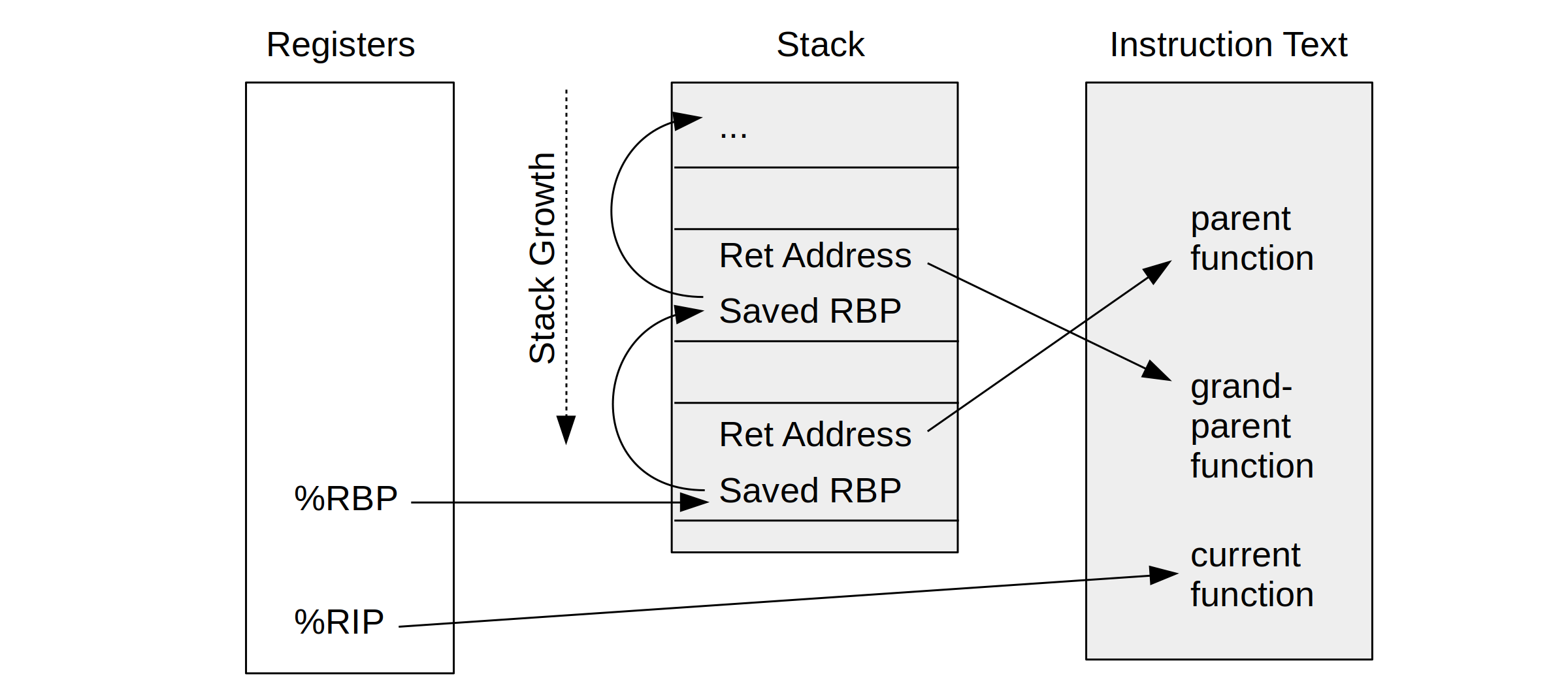
Эта техника обхода стека широко используется внешними профилировщиками и отладчиками, включая Linux perf и eBPF, и в конечном итоге визуализируется в виде flame graphs. Однако в ABI x86-64 есть сноска [12] о том, что такое использование регистров необязательно:
«Обычное использование
%rbpкак frame pointer для stack frame можно избежать, используя%rsp(stack pointer) для индексации в stack frame. Эта техника экономит две инструкции в прологе и эпилоге и делает доступным один дополнительный регистр общего назначения (%rbp).»
2004: Их удаление
В 2004 году один из разработчиков компилятора, Roger Sayle, изменил gcc так, чтобы он перестал генерировать frame pointers, написал:
«Простой патч ниже настраивает бэкенд i386 таким образом, что мы теперь по умолчанию используем эквивалент „
-fomit-frame-pointer -ffixed-ebp“ на 32-битных системах».
В 32-битных микропроцессорах i386 всего четыре регистра общего назначения, поэтому, освободив %ebp, вы переходите от четырех к пяти (или, если включить %si и %di, от шести к семи). Я уверен, что это дало большой прирост производительности, и не стал бы спорить против этого. Роджер назвал еще две причины этого изменения: Желание превзойти компилятор Intel icc и уверенность в том, что это не сломает отладчики (того времени), поскольку они поддерживали другие техники перемещения по стеку.
2005-2023: Зима сломанных профилей
Однако затем это изменение было применено и к x86-64 (64-битному), у которого было более дюжины регистров, и освобождение еще одного не принесло особой пользы. Кроме того, есть отладчики/профилировщики, которые это изменение сломало (обычно это системные профилировщики, а не специфические для языка). Как писал мой бывший коллега из Sun Microsystems Эрик Шрок (Schrock) в ноябре 2024г:
«На i386 у вас, по крайней мере, было преимущество в виде увеличения количества используемых регистров на 20%. В amd64 добавление 17-го регистра общего назначения не откроет совершенно новый мир оптимизаций компилятора. Вы просто сохраняете
pushl,movl, серию операций, которые (по очевидным причинам) сильно оптимизированы на x86. И для leaf routines (которые никогда не устанавливают кадр) это не проблема. Только в экстремальных обстоятельствах затраты (процессорное время и I-cache footprint) приводят к ощутимой выгоде - обстоятельства, при которых обычно все равно приходится прибегать к ассемблеру с ручным кодированием. Учитывая выгоду и относительную стоимость потери отладки, это вряд ли стоит того».
Schrock делает вывод:
«Когда люди начинают компилировать /usr/bin/ без frame pointers, это выходит из-под контроля».
Именно это и произошло в Linux, причем не только в /usr/bin, но и в /usr/lib и в коде приложений! Я уверен, что есть люди, которые слишком недавно пришли в индустрию, чтобы помнить времена до 2004 года, когда профилировщики «просто работали» без изменений в ОС и runtime.
2014: Java в огне
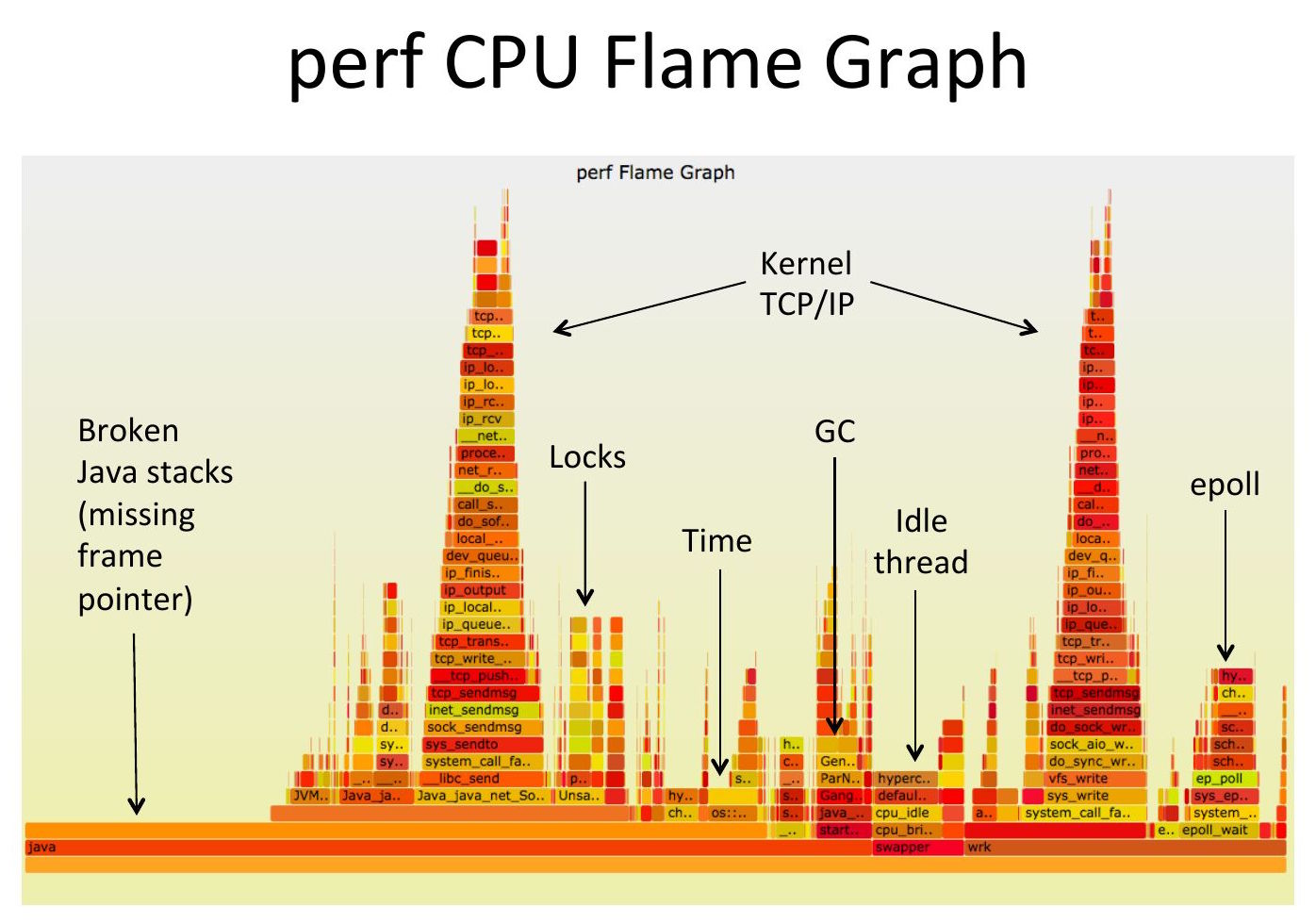
Когда я пришел в Netflix в 2014 году, я обнаружил, что отсутствие поддержки frame pointer в Java сломало все стеки приложений. В итоге я разработал исправление для компилятора JVM c2, которое Oracle переработала и добавила в качестве опции - -XX:+PreserveFramePointer в JDK8u60.
Хотя это изменение в Java привело к обнаружению бесчисленных преимуществ производительности в коде приложений, libc все еще ломала часть примеров и большинство стеков в off-CPU flame graphs. Я начал с компиляции собственной libc с frame pointers, а затем сотрудничал с Canonical, чтобы получить готовый libc для Ubuntu. Некоторое время я пропагандировал использование libc6-prof от Canonical, которая представляла собой libc6 с frame pointers.
2015-2020: Overhead
В рамках продакшена я провел множество тестов на увеличение производительности, о которых я уже рассказывал ранее: Накладные расходы при добавлении frame pointers ко всему (libc и Java) обычно составляли менее 1%, за одним исключением в 10%. Эти 10% приходились на необычное приложение, которое генерировало трассировку стека глубиной более 1000 фреймов (через Groovy), настолько глубокую, что она сломала perf-профилировщик Linux. Arnaldo Carvalho de Melo (Red Hat) добавил sysctl kernel.perf_event_max_stack специально для этой рабочей нагрузки Netflix. Это также была виртуальная машина, в которой отсутствовали низкоуровневые возможности профилирования аппаратного обеспечения, поэтому я не смог провести анализ циклов, чтобы подтвердить, что 10% были полностью основаны на указателях кадров.
Фактические накладные расходы зависят от вашей рабочей нагрузки. Другие пользователи сообщают о примерно 1% и около 2%. Микробенчмарки могут быть хуже всего, достигая 10%: Это меня не удивляет, поскольку они решают задачу выполнения небольшой функции в цикле, и добавление любых инструкций к этой функции может привести к тому, что она выйдет за пределы кэша L1 (или кэш-линий), что вызовет падение производительности. Если бы я анализировал такой микробенчмарк, то помимо анализа наблюдаемости (циклы, инструкции, PMU, PMCs, PEBS) я бы хотел провести эксперимент:
Чтобы проверить теорию I-cache spillover: Скомпилируйте микробенчмарк с frame pointers и без них и найдите дельту производительности. Затем постройте flame graph микробенчмарка, чтобы понять горячую функцию. Затем добавьте в горячую функцию немного встроенного ассемблера, в котором добавьте достаточное количество NOP в начале и конце, чтобы имитировать пролог и эпилог frame pointer (рекомендую написать их карандашом на стене вашего офиса), скомпилируйте ее без frame pointer, дизассемблируйте скомпилированный двоичный файл, чтобы убедиться, что эти NOP не были удалены, и теперь проверьте это. Если дельта производительности все еще велика (10%), вы подтвердили, что она вызвана эффектами кэша, и любой, кто работал на этом уровне в продакшне, скажет вам, что это соломинка, которая сломала спину верблюда. Не вините соломинку, в данном случае - frame pointers. Добавление чего угодно приведет к тому же эффекту. Мне, занимавшемуся этим раньше, это напоминает программирование на CSS: сделаешь небольшое изменение здесь, и все ломается, а ты часами гоняешься за собственным хвостом.
Другим экстремальным примером накладных расходов был бенчмарк Python scimark_sparse_mat_mult, в котором они могли достигать 10%. К счастью, это было проанализировано Andrii Nakryiko(Meta), который обнаружил, что это был необычный случай большой функции, в которой gcc переключился с %rsp-смещений на %rbp-относительные смещения, что требовало больше байт для хранения, вызывая проблемы с производительностью. Я слышал, что с тех пор это было исправлено, так что Python может снова включить фреймовые указатели по умолчанию.
Поскольку я видел, как frame pointers помогают найти выигрыш в производительности от 5 до 500%, типичная стоимость «менее 1%» (или даже 1 или 2%) легко оправдана. Но я бы предпочел, чтобы затраты были нулевыми, конечно! Возможно, мы достигнем этого с помощью будущих технологий, о которых я расскажу позже. А пока frame pointers - это самый практичный способ найти выигрыш в производительности уже сегодня.
А как насчет Linux на устройствах, где нет возможности профилирования или отладки, например на электрических зубных щетках? Конечно, компилируйте без frame pointers. Основные пользователи этого изменения - корпоративный Linux. Back-end серверы.
2022: Upstreaming, первая попытка
Другие крупные компании с командами разработчиков ОС и perf (Meta, Google) недвусмысленно намекали, что они уже включили frame pointers во все приложения годами ранее. (Так что на данный момент Google, Meta и Netflix используют свои собственные libc с frame pointers и могут пользоваться возможностями профилирования, которые большинство других компаний, не имеющих специализированных команд по ОС, не смогли реализовать. Разве мы не можем просто перенести это на более высокий уровень, чтобы все могли воспользоваться этим?
Существует целый ряд трудностей, когда вы берете изменения, которые «хорошо работают для меня», и пытаетесь сделать их по умолчанию для всех. Среди этих трудностей - то, что end-user компании не имеют четкого возврата инвестиций от сообщения вендору Linux о том, что они исправили, поскольку они уже исправили это. Я полагаю, что вложения совсем небольшие, мы ведь говорим об одном письме, верно?… Неверно! Ваше предложение превратилось в тему из 116 постов, где все делятся разными мнениями и требуют того-то и того-то, как мы убедились на собственном опыте. Для Fedora один человек попросил:
«Meta и/или Netflix должны предоставить инфраструктуру для стороннего репозитория, в котором изменения могут быть протестированы и проверены, а размер кода измерен».
(Имейте в виду, что Netflix даже не использует Fedora!).
Jonathan Corbet, который пишет лучшие статьи о Linux, подытожил это в статье “Fedora’s tempest in a stack frame”, которая настолько подробна, что я испытываю посттравматический синдром при ее прочтении. Хорошо, что сообщество Fedora хочет быть таким осторожным, но я бы предпочел потратить время на обсуждение создания чего-то лучшего, чем frame pointers, возможно, с привлечением ORC, LBR, eBPF и других технологий, чем так беспокоиться о том, чтобы плохо выглядеть в kitchen-sink бенчмарках, которым я бы не доверял в первую очередь.
2023, 2024: Frame Pointers в Fedora и Ubuntu!
Fedora пересмотрела предложение и на этот раз приняла его, став первым дистрибутивом, в котором восстановлены frame pointers. Спасибо!
Ubuntu также объявила об использовании frame pointers по умолчанию в Ubuntu 24.04 LTS. Спасибо!
В Arch Linux тоже есть возможность использовать frame pointers! Спасибо Даану де Мейеру (Meta).
Хотя это и устраняет проблему трассировки стека через библиотеки ОС, вы можете обнаружить, что ваше приложение по-прежнему не поддерживает трассировку стека, но это, как правило, гораздо проще исправить. В Java, например, есть опция -XX:+PreserveFramePointer. Были способы заставить Golang поддерживать frame pointers, но эта опция стала использоваться по умолчанию много лет назад.
2034+: За пределами Frame Pointers
Есть не один способ пройтись по стеку. Об этом можно было бы написать отдельную статью в блоге, но я хочу кратко прокомментировать альтернативные варианты:
- LBR (Last Branch Record): Аппаратная функция Intel, которая была ограничена 16 или 32 кадрами. Большинство стеков приложений глубже, поэтому этот метод нельзя использовать для построения flame graphs, но это лучше, чем ничего. Я использую его в крайнем случае, так как он дает мне некоторые сведения о стеке.
- BTS (Branch Trace Store): Еще одна особенность Intel. Не ограничивается глубиной стека, но имеет накладные расходы на загрузку/сохранение памяти и обработку прерываний по переполнению буфера BTS.
- AET (Archetectural Event Trace): Еще одна разработка Intel. Это JTAG-based tracer, который может отслеживать низкоуровневые события процессора, BIOS и событий устройства, и, по-видимому, может использоваться также для трассировки стека. Я им не пользовался. (Я много лет работал в облаке, где не мог получить доступ ко многим вещам на уровне HW). Надеюсь, его можно настроить на вывод в основную память, а не только на физический порт отладки.
- DWARF: Двоичная отладочная информация, всегда использовалась в отладчиках. Обновление: я уже говорил, что для JIT runtime, таких как Java JVM, этого не существует, но другие отметили, что была проделана некоторая работа с JIT->DWARF. Я все еще не ожидаю, что это будет практично на загруженных продуктивных серверах, которые постоянно находятся в c2. Накладные расходы только на DWARF также высоки, поскольку он был разработан для использования не в реалтайме. Javier Honduvilla Coto (Polar Signals) проделал интересную работу, используя eBPF walker для снижения накладных расходов, но… Java.
- eBPF stack walking: Mark Wielaard (Red Hat) продемонстрировал на LinuxCon 2014 устройство для обхода стека Java JVM с помощью SystemTap, в котором внешний трассировщик обходил runtime без поддержки runtime или помощи. Очень круто. Это можно сделать и с помощью eBPF. Однако накладные расходы на производительность могут быть слишком высокими, так как это может означать большое количество чтений внутреннего пространства runtime из пользовательского пространства в зависимости от runtime. Кроме того, это будет хрупко; такие eBPF stack walkers должны поставляться с кодовой базой языка и поддерживаться вместе с ней.
- ORC (oops rewind capability): Новый облегчённый stack unwinder в ядре Linux, разработанный Josh Poimboeuf (Red Hat), который позволяет новым ядрам удалять frame pointers, сохраняя при этом перемещение по стеку. Возможно, вы используете ORC, не подозревая об этом; внедрение прошло гладко, поскольку код профилировщика ядра был обновлен для поддержки ORC (
perf_callchain_kernel()->unwind_orc.c) одновременно с его компиляцией для поддержки ORC. Разве ORC не могут вторгаться и в пользовательское пространство? - SFrames (Stack Frames): …именно это и делает SFrames: легкое раскручивание пользовательского стека на основе ORC. Недавно об этом рассказали Indu Bhagat (Oracle) и Steven Rostedt (Google). Я должен написать статью в блоге, посвященную SFrames.
- Shadow Stacks: Новая функция безопасности Intel и AMD, которая может быть настроена на перенос адресов возврата функций в отдельный стек HW, чтобы их можно было дважды проверить при возврате. Похоже, что такой стек HW может также обеспечить трассировку стека, без frame pointers.
- (И это еще не все).
Daan De Meyer (Meta) сделал хороший обзор различных программ для обхода стеков на Fedora wiki.
Что же дальше? Вот мои предположения:
- 2029: Ubuntu и Fedora выпускают новые версии с SFrames для компонентов ОС (включая libc) и снова отказываются от frame pointers. У нас будет пять лет преимуществ в производительности на основе фрейм-указателей и новые инновации, использующие стеки пользовательского пространства (например, более эффективное автоматическое сообщение об ошибках), и мы начнем работать с SFrames.
- 2034: Shadow stacks были включены по умолчанию для безопасности, а затем используются для трассировки всех стеков.
Заключение
Я могу сказать, что времена изменились, и теперь первоначальные причины 2004 года для отказа от frame pointers уже не актуальны в 2024 году. Эти причины заключались в том, что это значительно повышало производительность на i386, не ломало тогдашние отладчики (до появления eBPF) и считалось, что конкуренция с другим компилятором (icc) важна. Да, времена действительно изменились. Но я должен отметить, что один инженер, Eric Schrock, утверждал, что и в 2004 году, когда это было применено к x86-64, это не имело смысла, и я с ним согласен. Профилирование было сломано в течение 20 лет, и мы только сейчас это исправили.
Fedora и Ubuntu теперь вернули frame pointers, что является отличной новостью. Люди должны начать использовать эти релизы в 2024 году и обнаружат, что CPU flame graphs имеют больше смысла, Off-CPU flame graphs впервые работают, и другие новые вещи становятся возможными. Это также выигрыш для continuous profilers, поскольку им не нужно убеждать своих клиентов вносить изменения в ОС, чтобы профили заработали в полную силу.
Комментарии в Telegram-группе!