
- Репликация
- Репликация с несколькими ведущими узлами
- Конкурентные операции
- Секционирование
- Транзакции
- Слабые уровни изоляции
Секционирование
В случае очень больших наборов данных необходимо разбить данные на секции (partitions), иначе говоря, выполнить шардинг (sharding) данных.
Обычно секции задаются таким образом, что каждый элемент данных (запись, строка или документ) относятся ровно к одной секции. Фактически каждая секция сама по себе является маленькой БД, хотя база способна поддерживать операции, затрагивающие сразу несколько секций.
Основная цель секционирования данных — масштабируемость. Разные секции можно разместить в различных узлах в кластере, не предусматривающем разделения ресурсов. Следовательно, большой набор данных можно распределить по многим жестким дискам, а запросы — по многим процессорам.
При односекционных запросах каждый узел способен независимо выполнять запросы в своей секции, так что пропускную способность по запросам можно масштабировать просто добавлением новых узлов. Большие, сложные запросы можно распараллелить по нескольким узлам, хотя это намного сложнее.
Секционирование и репликация
Секционирование обычно идет бок о бок с репликацией, вследствие чего копии каждой из секций хранятся на нескольких узлах. Это значит, что, хотя каждая конкретная запись относится только к одной секции, храниться она может в нескольких различных узлах в целях отказоустойчивости.
Секционирование данных типа «ключ — значение»
Цель секционирования — равномерно распределить по узлам данные и загрузку по запросам. Если доли всех узлов примерно равны, то теоретически десять узлов смогут обрабатывать в десять раз больше данных и будут иметь в десять раз большую пропускную способность по чтению и записи, чем отдельный узел (без учета репликации).
Если же секционирование выполнено неравномерно, читай — на долю некоторых секций приходится больше данных или запросов, чем на долю других, — то оно называется асимметричным (skewed). Наличие асимметрии существенно снижает эффективность секционирования. В предельном случае вся нагрузка ляжет на одну секцию, так что девять из десяти узлов будут простаивать, а узким местом окажется единственный функционирующий узел. Секция с непропорционально высокой нагрузкой называется горячей точкой (hot spot).
Простейший способ избежать горячих точек — назначать узлы для записей случайным образом. Это приведет к равномерному распределению данных по узлам; но есть у такого подхода и большой недостаток: при чтении неизвестно, в каком узле находится конкретный элемент данных, вследствие чего приходится параллельно опрашивать все узлы.
Секционирование по диапазонам значений ключа
Один из методов секционирования — назначить каждой из секций непрерывный диапазон значений ключа (от какого-то минимального значения до какого-то максимального), подобно томам бумажной энциклопедии. Если вам известны границы между диапазонами, то можно легко определить, в какой секции содержится нужный ключ. Если вдобавок знать, с какими секциями какие узлы соотносятся, то можно выполнить запрос непосредственно к соответствующему узлу.
Диапазоны значений ключа не обязательно должны быть одинакового размера, поскольку данные могут быть распределены неравномерно.
Чтобы данные были распределены равномерно, границы секций должны быть подобраны в соответствии с данными.
Однако недостатком секционирования по диапазонам значений ключа является то, что некоторые паттерны доступа приводят к горячим точкам. Если ключ представляет собой метку даты/времени, то секции соответствуют отрезкам времени, например одна секция на день. В случаях, когда данные записываются в базу по мере получения значений от датчиков, все операции записи будут выполняться в одной секции (сегодняшней), вследствие чего эта секция окажется перегружена операциями записи, а остальные будут простаивать.
Чтобы избежать этой проблемы в базе данных, полученных с датчиков, необходимо использовать в качестве первого элемента ключа не метку даты/времени, а нечто иное. Например, можно предварить метку даты/времени названием датчика, и, как следствие, секционирование будет выполняться сначала по названию датчика, а только потом по времени.
Секционирование по хешу ключа
Многие распределенные базы данных, опасаясь асимметрии и горячих точек, используют для распределения ключей по секциям хеш-функцию.
Хорошая хеш-функция получает на входе асимметричные данные и возвращает равномерно распределенные значения.
В целях секционирования хеш-функция не должна быть криптографически стойкой: например, СУБД Cassandra и MongoDB используют MD5, а Voldemort — функцию Фаулера-Нола-Во.
При наличии подходящей хеш-функции для ключей можно поставить каждой секции в соответствие диапазон хешей (вместо диапазона ключей), и каждый ключ, чье значение находится в диапазоне данной секции, будет сохранен в ней.
Это хороший способ равномерного распределения ключей по секциям. Границы секций могут быть или распределены равномерно, или выбраны псевдослучайным образом (в последнем случае метод иногда называется согласованным хешированием (consistent hashing)).
Однако, к сожалению, при использовании для секционирования хеша ключа мы теряем удобное свойство секционирования по диапазонам значений ключа: возможность эффективно выполнять запросы по диапазонам. Смежные некогда ключи оказываются разбросаны по всем секциям, и порядок их сортировки теряется.
Асимметричные нагрузки и разгрузка горячих точек
Как уже обсуждалось выше, хеширование ключа для определения секции может несколько исправить ситуацию с горячими точками, но не избавиться от них полностью: в предельном случае, когда все операции записи и чтения выполняются для одного ключа, все запросы все равно приходятся на одну секцию.
Подобная нагрузка, вероятно, необычна, но не беспрецедентна: например, на сайтах соцсетей действия знаменитостей, насчитывающих миллионы подписчиков, могут вызывать бурю активности.
На сегодняшний день большинство информационных систем не умеют автоматически выравнивать подобную высоко асимметричную нагрузку, вследствие чего снижение асимметрии — обязанность приложения. Например, если известно, что конкретный ключ — очень горячий, то простейшим решением будет добавление в начало или конец этого ключа случайного числа. Простое двузначное десятичное число приведет к разбиению операций записи для ключа равномерно по 100 различным ключам, что позволит распределить их по разным секциям.
Однако при условии разбиения операций записи по различным ключам операциям чтения придется совершать дополнительные действия по чтению и объединению данных для всех этих ключей.
Секционирование и вторичные индексы
Ситуация осложняется в случае применения вторичных индексов. Вторичный индекс обычно не идентифицирует запись однозначно, а представляет собой скорее способ поиска вхождений конкретного значения: «найти все действия пользователя 123», «найти все статьи, содержащие слово hogwash», «найти все машины красного цвета» и т.д.
Основная проблема вторичных индексов — в том, что невозможно поставить их в четкое соответствие секциям. Существует два основных подхода к секционированию базы данных с вторичными индексами: секционирование по документам (document-based partitioning) и секционирование по термам (term-based partitioning).
Секционирование вторичных индексов по документам
Например, представьте, что у вас есть сайт для продажи подержанных автомобилей. У каждого описания есть уникальный ID — назовем его идентификатором документа, — и мы можем секционировать базу данных по этому идентификатору (например, ID с 0 по 499 — в секции 0, ID с 500 по 999 — в секции 1 и т. д.).
Необходимо, чтобы пользователи могли искать автомобили, фильтруя их по цвету и производителю, поэтому нам понадобится вторичный индекс по color и make. Достаточно будет описать индекс, БД может выполнять индексацию автоматически.
При таком подходе к индексации все секции совершенно самостоятельны: каждая секция поддерживает свои собственные вторичные индексы, охватывающие только документы из этой секции. Данные из других секций значения для нее не имеют.
При необходимости выполнить запись в БД — для добавления, удаления или обновления документа — приходится работать только с секцией, в которой содержится идентификатор записываемого документа. Поэтому секционированный по документам индекс также называется локальным индексом (local index), в отличие от глобальных индексов (global index).
Однако чтение из индекса, секционированного по документам, требует внимательности, не все данные для поиска будут находится в одной секции. Следовательно, при поиске таких автомобилей придется выполнять запрос ко всем секциям с объединением полученных результатов.
Подобная методика выполнения запросов к секционированной базе данных известна под названием фрагментированной (scatter/gather), и запросы на чтение при ней могут оказаться весьма затратными.
Даже при параллельном выполнении запросов к секциям фрагментированное чтение часто приводит к усилению «хвостового» времени ожидания.
Секционирование вторичных индексов по термам
Вместо отдельного вторичного индекса для каждой секции (локальные индексы) можно сконструировать глобальный индекс (global index), охватывающий данные из всех секций.
Однако такой индекс нельзя хранить в одном узле, иначе он превратится в узкое место и сведет на нет все выгоды от секционирования. Глобальный индекс тоже нужно секционировать, но его можно секционировать не так, как индекс по первичному ключу.
Такая разновидность индекса называется секционированной по терму (term-partitioned), поскольку искомый терм определяет секционирование индекса.
Название «терм» (term) берет свое начало от полнотекстовых индексов, в которых термами являются все слова, встречающиеся в документе.
Как и ранее, мы можем секционировать индекс по самому терму или по его хешу. Первое может оказаться полезным для поисков по диапазону, а второе обеспечивает более равномерное распределение нагрузки.
Преимуществ глобальных (секционированных по терму) индексов над секционированными по документу состоит в повышении производительности чтения: вместо фрагментированного чтения по всем секциям клиенту нужно только выполнить запрос к секции, содержащей нужный терм.
Однако недостаток глобальных индексов — в замедлении и усложнении операций записи, поскольку запись в отдельный документ может затронуть несколько секций индекса (все термы в документе могут находиться в разных секциях и в разных узлах).
На практике обновления глобальных индексов часто выполняются асинхронно (то есть при чтении индекса вскоре после операции записи выполненные изменения могут оказаться еще не видны).
Перебалансировка секций
С течением времени положение дел в базе данных меняется:
- количество обрабатываемых запросов растет, так что для возросшей нагрузки понадобятся дополнительные процессоры;
- размер набора данных растет, поэтому для его хранения понадобятся дополнительные жесткие диски и оперативная память;
- некоторые компьютеры испытывают сбои, вследствие чего другим компьютерам приходится брать на себя их обязанности.
Все эти изменения требуют перемещения данных и перенаправления запросов из одних узлов в другие. Процесс перемещения нагрузки с одного узла в кластере на другой называется перебалансировкой (rebalancing).
Перебалансировка обычно должна отвечать определенным минимальным требованиям:
- после перебалансировки нагрузка (хранение данных, запросы на чтение и запись) должна быть распределена равномерно по узлам кластера;
- база данных должна продолжать принимать запросы на чтение и запись во время перебалансировки;
- между узлами должно перемещаться ровно то количество данных, которое необходимо, ради ускорения перебалансировки и минимизации нагрузки по вводу/выводу на сеть и жесткие диски.
Методики перебалансировки
Как делать не следует: хеширование по модулю N
При секционировании по хешу ключа, как мы упоминали ранее, лучше всего разбить возможные хеши на диапазоны и поставить в соответствие каждому диапазону секцию (например, key относится к секции 0, если 0 ≤ hash(key) < b0, к секции 1, если b0 ≤ hash(key) < b1 и т. д.).
Почему мы не используем просто mod?
Проблема с методом mod N состоит в том, что при изменении количества N узлов придется перенести большинство ключей из одного узла в другой.
Например, допустим, hash(key) = 123456. Если изначально у нас десять узлов, то этот ключ окажется в узле номер 6. Когда система вырастет до 11 узлов, этот ключ придется перенести в узел 3, а когда вырастет до 12 — в узел 0. Такие частые перемещения делают перебалансировку очень дорогим удовольствием.
Нам требуется подход, при котором не нужно перемещать данные больше, чем необходимо.
Фиксированное количество секций
К счастью, существует очень простое решение: создать намного больше секций, чем узлов в системе, и распределить по нескольку секций на каждый узел. Например, можно разбить работающую на кластере из десяти узлов базу данных на 1000 секций из расчета по 100 секций на каждый узел.
Тогда добавляемый в кластер новый узел может «позаимствовать» по нескольку секций у каждого из существующих узлов на время, до тех пор пока секции не станут снова распределены равномерно. При удалении узла из кластера выполняется обратный процесс.
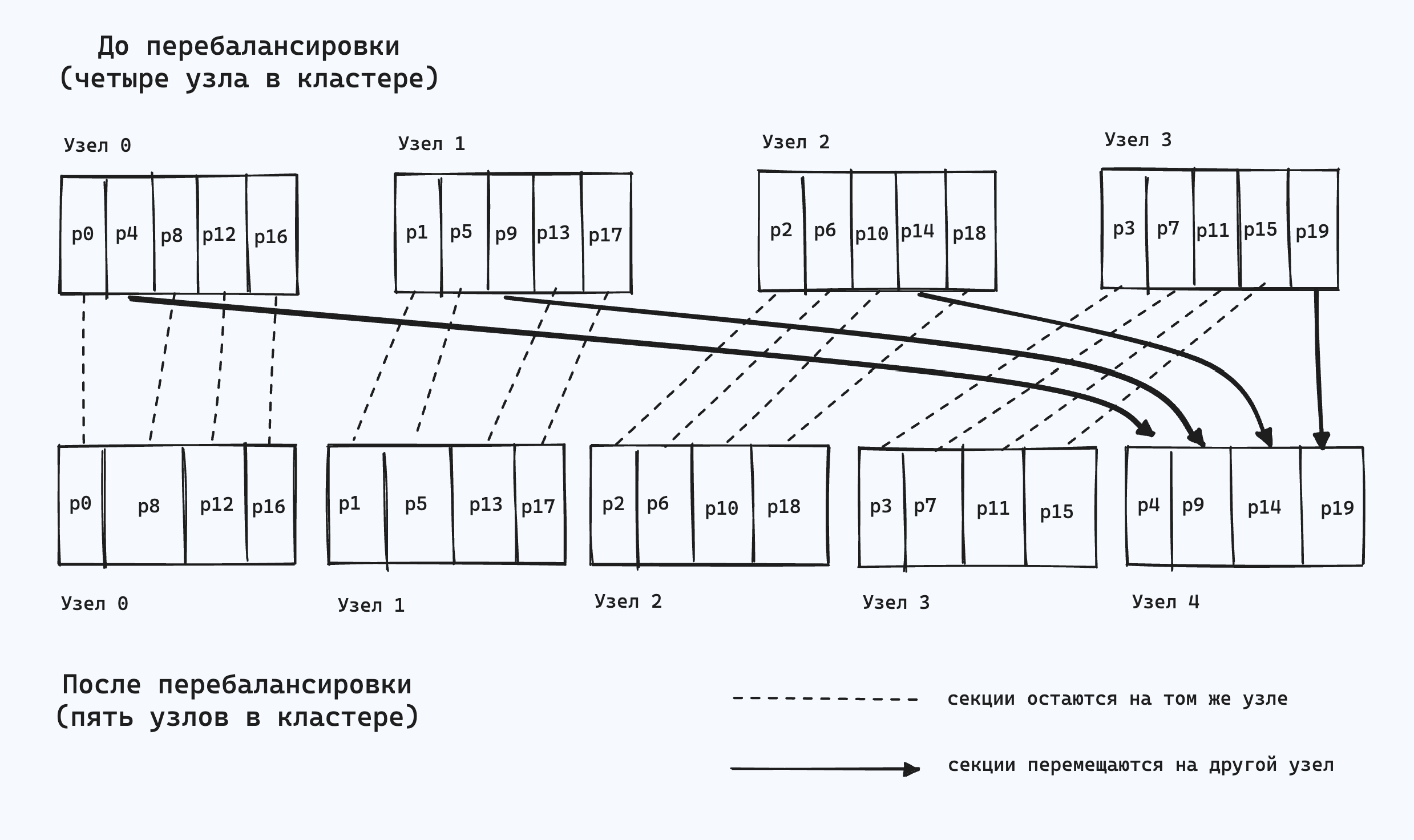
Между узлами перемещаются только секции целиком. Количество последних не меняется, как и соответствие ключей секциям. Единственное, что меняется, — распределение секций по узлам. Это не происходит мгновенно (перемещение значительного количества данных по сети занимает некоторое время), и, как следствие, для всех происходящих во время перемещения операций записи и чтения используется старое распределение секций.
При такой конфигурации количество секций обычно задается при первой настройке базы данных и потом не меняется. Хотя, в принципе, секции можно разбивать и сливать, эксплуатация фиксированного количества секций проще, так что многие БД с фиксированным количеством секций предпочитают не реализовывать разбиение секций вообще.
Выбор правильного количества секций особенно сложен при сильной изменчивости общего размера набора данных. Поскольку в каждой секции содержится фиксированная доля всех данных, размер секций растет пропорционально общему объему данных в кластере. При очень большом размере секций перебалансировка и восстановление после отказов узлов требуют значительных ресурсов. А слишком маленький размер секций приводит к слишком большим накладным расходам.
Динамическое секционирование
Для использующих динамическое секционирование БД фиксированное количество секций с фиксированными границами было бы очень неудобно: если вы зададите границы неправильно, то можете оказаться в ситуации, когда все данные находятся в одной секции, а остальные секции пусты. А перепланировка границ секций вручную — очень утомительная работа.
Поэтому секционированные по диапазонам значений ключа базы данных, такие как HBase и RethinkDB, создают секции динамически.
Когда размер секции перерастает заданный размер, она разбивается на две секции, таким образом, чтобы примерно половина данных оказалась в одной, а половина — в другой. И наоборот, если значительное количество данных удаляется и секция становится меньше определенного порогового значения, то ее можно слить с соседней секцией.
Каждая секция относится к какому-либо узлу, причем к одному узлу может относиться несколько секций, как в случае с фиксированным количеством секций. После разбиения большой секции одну из ее частей можно переместить в другой узел, чтобы сбалансировать нагрузку.
Преимуществом динамического секционирования является адаптация количества секций к общему объему данных. Если данных немного, то достаточно небольшого количества секций и накладные расходы невелики; в противном случае размер каждой секции ограничивается заранее задаваемым максимумом.
Динамическое секционирование подходит не только для данных, секционированных по диапазонам значений ключа, но и может с равным успехом использоваться для хеш-секционированных данных.
Секционирование пропорционально количеству узлов
При динамическом секционировании количество секций пропорционально размеру набора данных, поскольку размеры всех секций поддерживаются с помощью процессов разбиения и слияния в пределах фиксированных минимума и максимума. С другой стороны, при фиксированном количестве секций, размер каждой секции пропорционален размеру набора данных. В обоих случаях количество секций не зависит от количества узлов.
При третьем возможном варианте, используемом в СУБД Cassandra и Ketama, количество секций пропорционально количеству узлов — другими словами, на каждый узел приходится фиксированное количество секций. В этом случае размеры всех секций растут пропорционально размеру набора данных, если количество узлов остается неизменным, но при увеличении количества узлов секции снова уменьшаются. Поскольку больший объем данных обычно требует для хранения большего количества узлов, такой подход обеспечивает практически постоянные размеры отдельных секций.
При добавлении в кластер новый узел случайным образом выбирает фиксированное количество существующих секций для разбиения, после чего забирает по одной половине каждой из разбиваемых секций, оставляя вторые половины на месте. Получаемые в результате разбиения могут оказаться неравными, но при усреднении по большому количеству секций (по умолчанию в СУБД Cassandra 256 секций на узел) новый узел забирает у других узлов равную долю общей нагрузки. В Cassandra 3.0 появился другой алгоритм перебалансировки, позволяющий избежать неравных разбиений.
Выбор границ секций случайным образом требует использования хеш-секционирования (чтобы выбрать границы на основе диапазона чисел, возвращаемых хеш-функцией). Безусловно, такой подход лучше всего соответствует исходному определению согласованного хеширования. Новейшие хеш-функции позволяют достичь того же результата с меньшей избыточностью метаданных.
Маршрутизация запросов
Откуда клиент, выполняющий запрос, знает, к какому узлу ему нужно подключиться? При перебалансировке секций распределение их по узлам меняется. Необходим какой-то «наблюдатель сверху» за этими изменениями.
Это частный случай более общей задачи, называемой обнаружением сервисов (service discovery), относящейся не только к базам данных. Задача касается любого доступного программного обеспечения, предназначенного для обращения по сети, особенно стремящегося к высокой доступности (при работе на нескольких машинах в избыточной конфигурации).
На высоком уровне существует несколько различных способов решения этой задачи
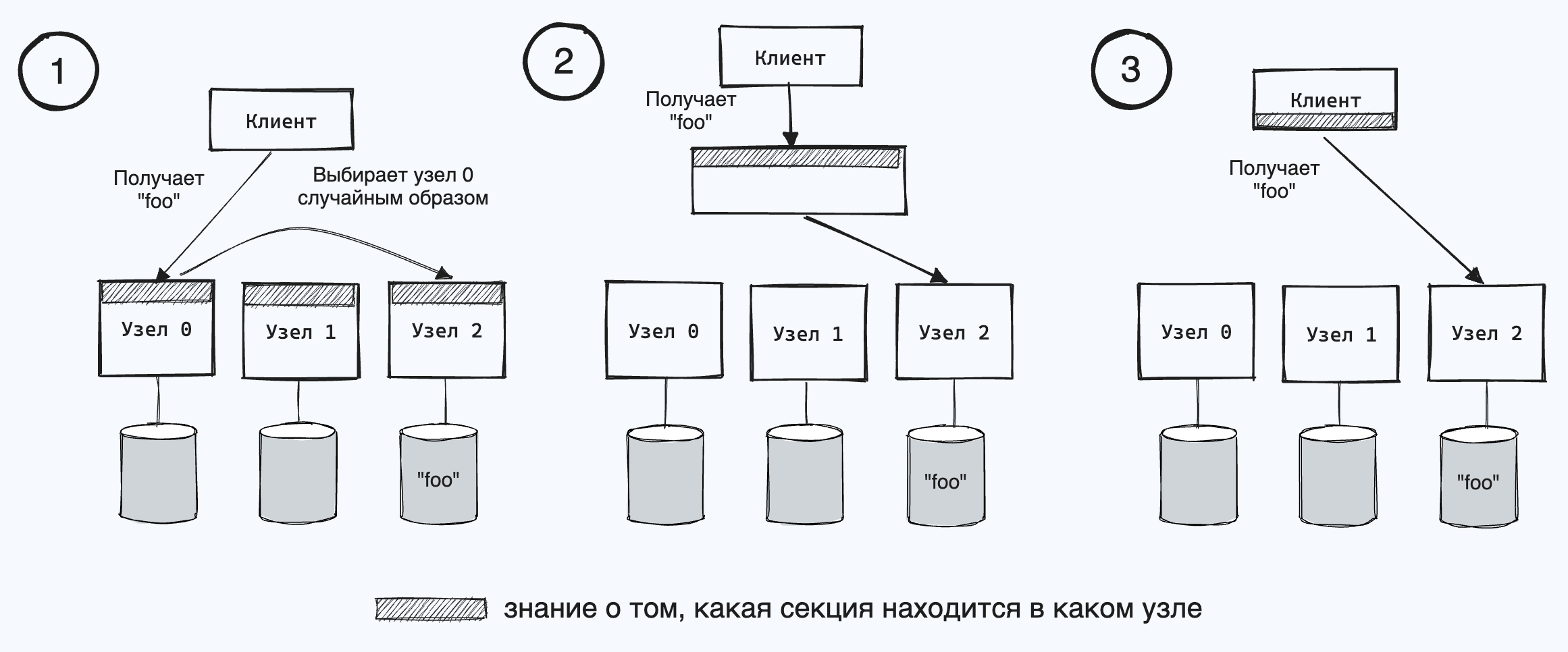
- Разрешить клиентам обращаться к любому узлу (например, с помощью циклического балансировщика нагрузки). Если на этом узле случайно окажется секция, которая нужна для ответа на запрос, то он обработает запрос непосредственно, в противном случае перенаправит его соответствующему узлу, получит от него ответ и переправит его клиенту.
- Отправлять все поступающие от клиентов запросы сначала маршрутизирующему звену, которое определяет, какой узел должен обрабатывать данный запрос, и переправляет его соответствующим образом. Это маршрутизирующее звено само не обрабатывает никаких запросов, а служит только учитывающим секции балансировщиком нагрузки.
- Потребовать, чтобы клиенты учитывали секционирование и распределение секций по узлам. В этом случае клиент может подключаться непосредственно к соответствующему узлу, без всяких посредников.
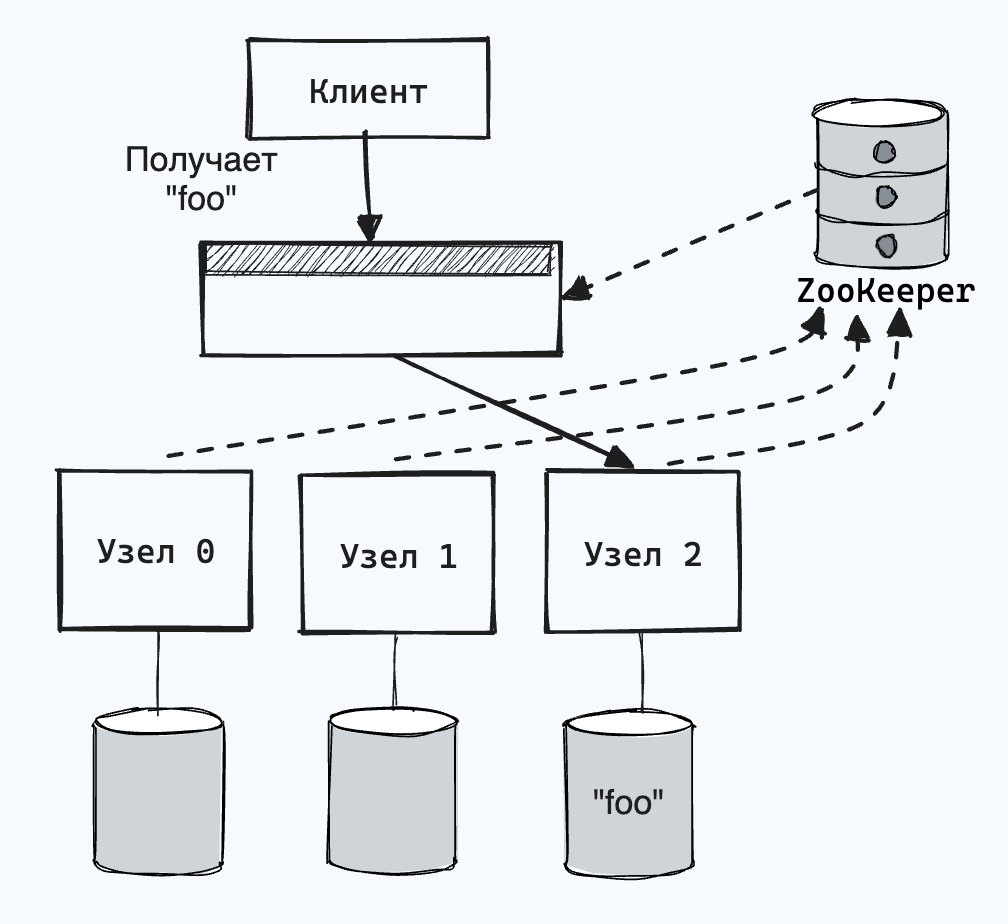
Многие распределенные информационные системы используют для отслеживания этих метаданных кластера отдельный сервис координации, например ZooKeeper.
Все узлы регистрируются в сервисе, который поддерживает актуальную карту соответствий секций узлам. Другие действующие лица, например маршрутизирующее звено или учитывающий секции клиент, могут подписываться на данную информацию в ZooKeeper. При каждой смене узла-владельца секции или добавлении/удалении узла сервис оповещает маршрутизирующее звено, так что маршрутизация остается актуальной.
Архитектура MongoDB аналогична, но основана на собственной реализации сервера конфигураций и демонов mongos в качестве маршрутизирующего звена.
Cassandra и Riak применяют другой подход: используют для обмена сообщениями между узлами gossip-протокол для распространения всех изменений состояния кластера.
Параллельное выполнение запросов
Реляционные базы данных с массово-параллельной архитектурой (massively parallel processing, MPP), часто используемые для аналитики, поддерживают гораздо более сложные типы запросов. Типичный запрос склада данных содержит несколько операций соединения, фильтрации, группировки и агрегирования. Оптимизатор запросов MPP разбивает этот сложный запрос на несколько стадий выполнения и секций, и многие из них можно выполнять параллельно в различных узлах кластера БД. Подобный параллелизм приносит особенную выгоду запросам, для которых требуется просмотр больших частей набора данных.
Резюме
Цель секционирования заключается в распределении нагрузки по данным и запросам равномерно по нескольким машинам, а также в том, чтобы избежать горячих точек (узлов с непропорционально высокой нагрузкой). Это требует выбора подходящей для набора данных схемы секционирования и перебалансировки секций при добавлении или удалении узлов из кластера.
Два основных подхода к секционированию
- Секционирование по диапазонам значений ключа, при котором ключи сортируются и секция содержит все ключи, начиная с определенного минимума до определенного максимума. Преимущество сортировки состоит в возможности выполнять эффективные запросы по диапазонам; но если приложение часто обращается к расположенным близко (в соответствии с сортировкой) ключам, то возникает риск возникновения горячих точек.
При этом подходе обычно производится динамическая перебалансировка секций с помощью разбиения диапазона на два поддиапазона в случае, когда секция становится слишком велика. - Хеш-секционирование, при котором вычисляется хеш-функция каждого ключа и к каждой секции относится определенный диапазон хешей. Этот метод нарушает упорядоченность ключей, делая запросы по диапазонам неэффективными, но позволяет более равномерно распределять нагрузку.
- При хеш-секционировании часто заранее создается фиксированное количество секций, по нескольку для каждого узла, а при добавлении или удалении узлов между узлами часто перемещаются целые секции. При этом также можно использовать динамическое секционирование.
Возможны и гибридные подходы, например с составным ключом: применение одной части ключа для идентификации секции, а другой — для определения порядка сортировки.
Два основных метода секционирования вторичных индексов
- Секционирование индексов по документам (локальные индексы). Вторичные индексы хранятся в одной секции с первичным ключом и значением. Это значит, что при операции записи нужно обновлять только одну секцию, но чтение вторичного индекса требует фрагментированного чтения по всем секциям.
- Секционирование индексов по термам (глобальные индексы), при котором вторичные индексы секционируются отдельно, с использованием индексированных значений. Элемент этого вторичного индекса может включать записи из всех секций первичного ключа. При записи документа приходится обновлять несколько секций вторичного индекса, однако результат чтения можно выдать из одной секции.
Источники
Комментарии в Telegram-группе!