
- Репликация
- Репликация с несколькими ведущими узлами
- Конкурентные операции
- Секционирование
- Транзакции
- Слабые уровни изоляции
Заметки из книги Клеппмана “Высоконагруженные приложения”.
В этой части: Репликация с несколькими ведущими узлами и репликация без ведущих узлов. Зачем такой подход нужен и какие сложности несет; Обнаружение и исправление конфликтов; Как собрать кворум и чем он поможет.
Репликация с несколькими ведущими узлами
У репликации с ведущим узлом есть один крупный недостаток: только один ведущий узел, через который должны проходить все операции записи. Если подключиться к узлу невозможно, например, из-за разрыва сети между вами и ведущим узлом, то нельзя выполнить и запись в базу данных.
Напрашивающееся расширение модели репликации с ведущим узлом — разрешение приема запросов на запись более чем одному узлу.
Репликация будет выполняться так же, как и ранее: каждый узел, обрабатывающий операцию записи, должен перенаправлять информацию о данных изменениях всем остальным узлам. Это называется схемой репликации с несколькими ведущими узлами (multi-leader replication), или репликацией типа «главный — главный» (master — master), или репликацией типа «активный/активный» (active/active replication). При такой схеме каждый из ведущих узлов одновременно является ведомым для других ведущих.
В схеме с несколькими ведущими узлами можно установить ведущий узел в каждом из ЦОДов. Внутри каждого из ЦОДов используется обычная репликация типа «ведущий — ведомый»; между ЦОДами ведущий узел каждого ЦОДа реплицирует свои изменения ведущим узлам в других ЦОДах.
У репликации с несколькими ведущими узлами есть свои преимущества. Однако она имеет и серьезный недостаток: одни и те же данные могут одновременно модифицироваться в двух различных ЦОДах, и такие конфликты записи необходимо разрешать.
Другая ситуация, подходящая для использования репликации с несколькими ведущими узлами, — приложения, которые должны продолжать работать, даже будучи отключенными от Интернета.
Обработка конфликтов записи
Основная проблема репликации с несколькими ведущими узлами — возможность возникновения конфликтов записи, которые требуют разрешения.
Асинхронное и синхронное обнаружение конфликтов
В базе данных с одним ведущим узлом вторая операция записи будет или заблокирована и ей придется ждать завершения первой, или преждевременно прекращена, так что пользователю нужно ее повторить.
С другой стороны, в схеме с несколькими ведущими узлами обе операции записи завершаются успешно, а конфликт обнаруживается асинхронно в какой-то более поздний момент времени. В этот момент, вероятно, уже слишком поздно просить пользователя разрешить его.
В принципе, можно сделать обнаружение конфликтов синхронным, то есть ждать репликации операции записи на все реплики, прежде чем сообщать пользователю об ее успешном завершении. Однако при этом потеряется главное преимущество репликации с несколькими ведущими узлами: возможность независимой обработки операций записи каждой репликой. Вместо синхронного обнаружения конфликтов можно просто применить репликацию с одним ведущим узлом.
Предотвращение конфликтов
Простейшая стратегия для конфликтов — просто избегать их: если приложение способно гарантировать, что все операции изменения конкретной записи проходят через один и тот же ведущий узел, то конфликт просто невозможен. Поскольку многие реализации репликации с несколькими ведущими узлами не очень хорошо разрешают конфликты, зачастую предотвращение конфликтов — рекомендуемый подход.
Например, если в приложении пользователь может редактировать собственные данные, то необходимо обеспечить, чтобы запросы от конкретного человека всегда маршрутизировались на один и тот же ЦОД и применяли ведущий узел последнего для чтения и записи.
Сходимость к согласованному состоянию
База данных с одним ведущим узлом применяет операции записи в последовательном порядке: при наличии нескольких изменений одного поля последняя по времени операция записи определяет итоговое значение этого поля.
В схеме с несколькими ведущими узлами нельзя задать порядок операций записи, так что непонятно, каким должно быть итоговое значение.
Если все реплики просто будут применять операции записи в том порядке, в котором они эти операции записи получают, то база данных в конце концов окажется в несогласованном состоянии.
Следовательно, база должна разрешать конфликт конвергентным способом, то есть все реплики должны сойтись к одному значению после репликации всех изменений.
Существует множество способов конвергентного разрешения конфликтов.
- Присвоить каждой операции записи уникальный идентификатор (например, метку даты/времени, случайное длинное число, UUID или хеш ключа и значения), после чего просто выбрать операцию («победителя») с максимальным значением этого идентификатора, а остальные отбросить. В случае использования метки даты/времени в качестве идентификатора этот метод известен под названием «выигрывает последний» (last write wins, LWW). Хотя этот подход очень популярен, ему свойственно терять данные.
- Присвоить уникальный идентификатор каждой реплике и считать, что у исходящих от реплик с большим номером операций записи есть приоритет перед теми, которые исходят от реплик с меньшим. Этот подход также приводит к потерям данных.
- Каким-либо образом слить значения воедино, например, выстроить их в алфавитном порядке, после чего выполнить их конкатенацию
- Заносить конфликты в заданную в явном виде структуру данных для хранения и написать код приложения, который бы разрешал конфликты позднее (возможно, спрашивая для этого пользователя).
Пользовательская логика разрешения конфликтов
Поскольку то, как лучше всего разрешить конфликт, зависит от приложения, большинство программных средств репликации с несколькими ведущими узлами позволяют создать логику разрешения конфликтов в коде приложения. Этот код может выполняться при записи или чтении.
- При записи. При обнаружении конфликта в журнале реплицированных изменений СУБД вызывает обработчик конфликтов.
- При чтении. При обнаружении конфликта система сохраняет информацию обо всех конфликтующих операциях записи. При следующей операции чтения все эти различные версии данных возвращаются приложению. Далее оно может спросить пользователя или разрешить конфликт автоматически, после чего записать результаты обратно в БД.
Подобное разрешение конфликтов выполняется обычно на уровне отдельных строк или документов, а не транзакций в целом. Следовтельно, в случае транзакции, выполняющей атомарно несколько различных операций записи, каждая операция рассматривается отдельно для целей разрешения конфликтов.
Автоматическое разрешение конфликтов
- Бесконфликтные реплицируемые типы данных (conflict-free replicated datatype, CRDT) — семейство структур данных для множеств, ассоциативных словарей, упорядоченных списков, счетчиков и др., допускающие конкурентное редактирование несколькими пользователями и автоматически разрешающие конфликты разумным образом. Некоторые из CRDT были реализованы в Riak 2.0.
- Объединяемые хранимые структуры данных (mergeable persistent data structures) обеспечивают отслеживание истории явным образом аналогично системе контроля версий Git и используют трехстороннюю функцию слияния (в отличие от двухстороннего слияния в CRDT).
- Операциональное преобразование (operational transformation) представляет собой алгоритм разрешения конфликтов, используемый в таких приложениях для совместного редактирования, как Etherpad и Google Docs. Он был спроектирован специально для совместного редактирования упорядоченного списка элементов, например перечня букв, составляющего текстовый документ.
Топологии репликации с несколькими ведущими узлами
Топология репликации (replication topology) описывает пути, по которым операции записи распространяются с одного узла на другой.
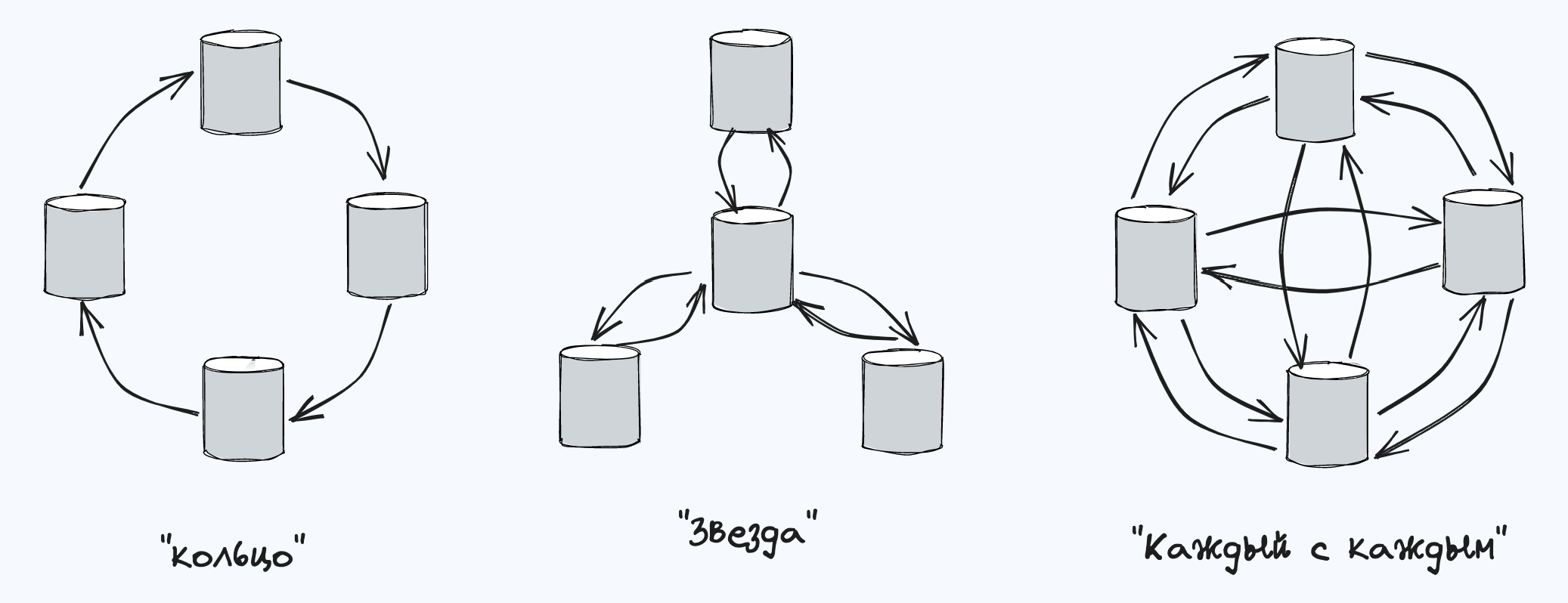
Проблема топологий типа «кольцо» и «звезда» заключается в следующем: отказ даже одного узла способен прервать поток сообщений репликации между другими узлами, делая связь между ними невозможной вплоть до момента его восстановления.
Репликация без ведущего узла
Обсуждавшиеся до сих пор подходы к репликации — с одним ведущим узлом и с несколькими — основаны на идее, что клиент отправляет запрос на запись одному узлу (ведущему), а СУБД берет на себя дублирование этой операции на всех остальных репликах. Ведущий узел определяет порядок обработки операций записи, а ведомые применяют полученные от ведущего операции записи в том же порядке.
Некоторые системы хранения данных используют другой подход, отказываясь от концепции ведущего узла и позволяя непосредственное поступление информации об операциях записи на все реплики. Такая архитектура снова вошла в моду после того, как Amazon задействовал ее для своей предназначенной для внутреннего использования системы Dynamo. Поэтому подобный тип БД называют Dynamo-подобной базой данных (Dynamo-style database).
В некоторых реализациях репликации без ведущего узла клиент непосредственно отправляет информацию о своих операциях записи на несколько реплик, в то время как для остальных данную манипуляцию от имени клиента совершает узел-координатор. Однако он, в отличие от БД с ведущим узлом, не навязывает определенный порядок операций записи.
Запись в базу данных при отказе одного из узлов
Представьте, что у вас есть БД с тремя репликами, одна из которых в настоящий момент недоступна — допустим, она перезагружается для установки обновления системы.
В случае схемы репликации с ведущим узлом при необходимости продолжать обработку операций записи придется выполнить восстановление после отказа.
С другой стороны, в схеме репликации без ведущего узла восстановления после отказа не существует.
Теперь представьте, что бывший недоступным узел снова работает и клиенты начинают читать из него данные. В нем отсутствует информация обо всех операциях записи, выполнявшихся, когда он не функционировал. Следовательно, при чтении из него вы рискуете получить в ответ устаревшие значения.
Для решения указанной проблемы при чтении из базы данных клиенты отправляют запросы не к одной реплике, а сразу к нескольким узлам параллельно. При этом клиент может получить различные ответы от разных узлов, то есть актуальные значения от одного узла и устаревшие от другого. Чтобы определить, какое значение новее, используются номера версий.
Разрешение конфликтов при чтении и антиэнтропия
Схема репликации должна обеспечивать копирование в конечном итоге всех данных в каждую из реплик. Каким образом ранее недоступный узел после возобновления работы может наверстать пропущенные им операции записи?
- Разрешение конфликтов при чтении. Клиент, читающий данные с нескольких узлов параллельно, способен обнаружить все устаревшие ответы. Клиент понимает, что значение реплики устарело, и записывает в нее более новое значение.
- Процесс противодействия энтропии В некоторых системах есть фоновый процесс, постоянно выискивающий различия в данных между репликами и копирующий отсутствующие данные из одной реплики в другую. В отличие от журнала репликации при репликации с ведущим узлом, подобный процесс противодействия энтропии (anti-entropy process) не копирует информацию об операциях записи в каком-либо определенном порядке, а перед копированием данных может возникнуть значительная задержка.
Без процесса противодействия энтропии редко читаемые значения могут отсутствовать в некоторых репликах, что приводит к снижению сохраняемости данных, поскольку разрешение конфликтов при чтении выполняется только при чтении значения приложением.
Операции записи и чтения по кворуму
Если бы была уверенность, что все успешные операции записи попадут как минимум на две реплики из трех, то устаревшей оказалась бы максимум одна реплика. Следовательно, при чтении данных из двух реплик можно быть уверенными: хотя бы одна из двух содержит актуальные данные. Если третья реплика не функционирует или отвечает слишком медленно, то операции чтения все равно будут продолжать возвращать актуальные значения.
Говоря более общим языком, при наличии n реплик операция записи, чтобы считаться успешной, должна быть подтверждена w узлами, причем мы должны опросить как минимум r узлов для каждой операции чтения (в нашем примере n = 3, w = 2, r = 2).
Если w + r > n, то можно ожидать: полученное при чтении значение будет актуальным, поскольку хотя бы один из r узлов, из которых мы читаем, должен оказаться актуальным. Операции записи и чтения, удовлетворяющие этому соотношению значений r и w, называются операциями чтения и записи по кворуму(strict quorum).
Можно рассматривать r и w как минимальные количества «голосов», необходимых для признания операции чтения или записи приемлемой.
Чаще всего n делают равным нечетному числу (обычно 3 или 5), а w = r = (n + 1) / 2 (округленному в большую сторону).
Можно менять эти числа. Например, при нагрузке, состоящей из нескольких операций записи и большого количества операций чтения, может быть выгодно задать w = n и r = 1. Такие показатели ускорят операции чтения, но всего лишь один отказавший узел приведет к сбою всей базы данных.
Условие кворума, w + r > n, придает системе устойчивость к недоступности узлов:
- при w < n можно продолжать обрабатывать информацию об операциях записи в случае недоступности узла;
- при r < n можно продолжать обрабатывать информацию об операциях чтения в случае недоступности узла;
- при n = 5, w = 3, r = 3 система может позволить себе два недоступных узла.
- обычно информация об операциях чтения и записи отправляется параллельно всем n репликам. Параметры w и r определяют, подтверждения от какого количества узлов мы будем ждать: то есть сколько узлов из n должны подтвердить успех, прежде чем можно будет считать операцию чтения или записи успешной в целом.
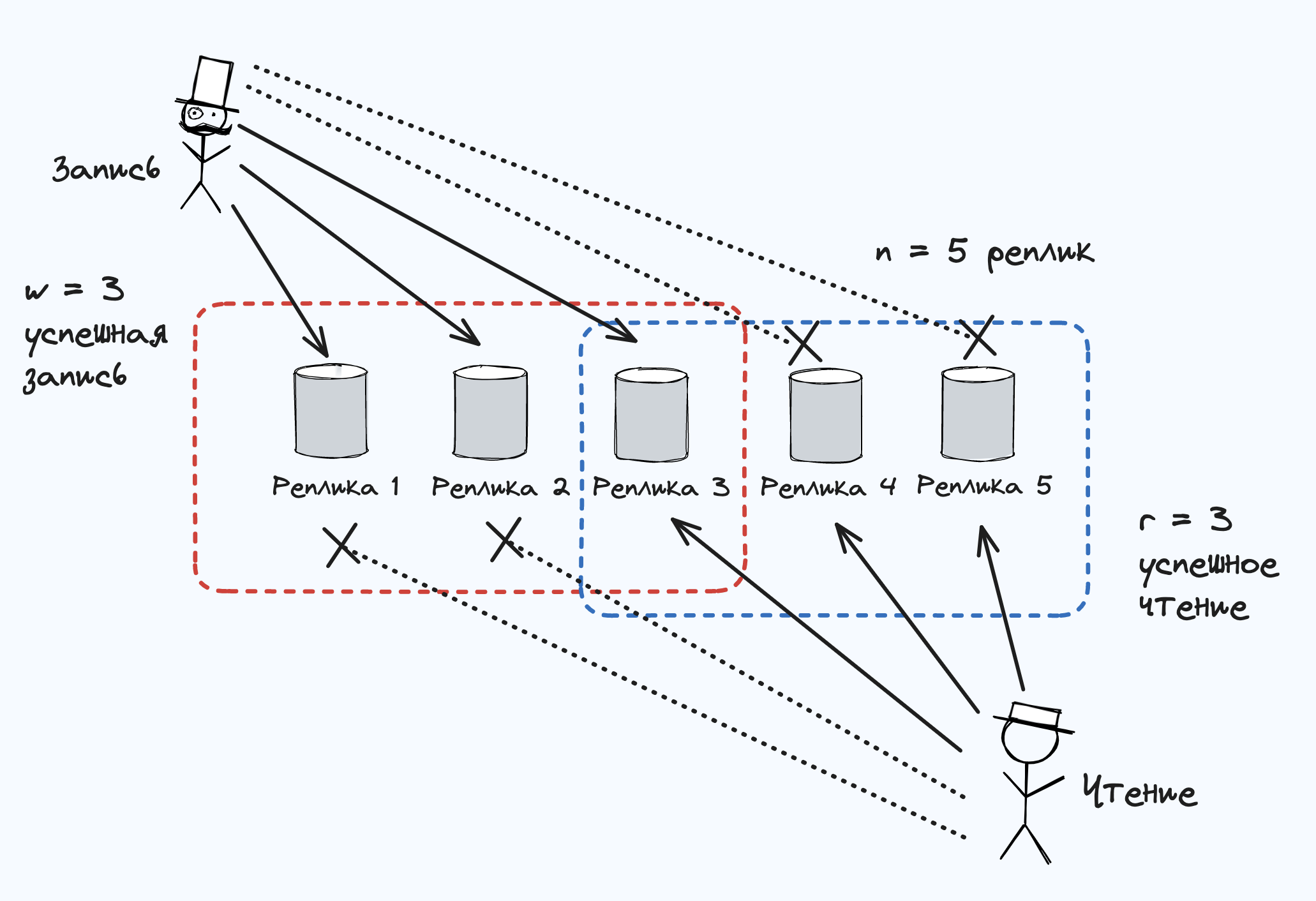
При w + r > n как минимум одна из читаемых r реплик точно получила информацию о самой последней успешной операции записи
Если доступно меньшее количество узлов, чем требуемое w или r, то операции записи или чтения вернут ошибку. Узел может быть недоступен по множеству причин: из-за того что отключен (произошел фатальный сбой, или отключено питание), вследствие ошибки при выполнении операции (например, нельзя записать данные из-за переполнения диска), в связи с разрывом сетевого соединения между клиентом и узлом или по любой из многих других причин. Нас интересует только, вернул ли узел ответ об успешном выполнении, нет нужды дифференцировать различные виды отказов.
Ограничения согласованности по кворуму
При наличии n реплик и выборе таких w и r, что w + r > n, можно, вообще говоря, ожидать возврата каждой операцией чтения наиболее свежего значения из записанных для данного ключа. Дело вот в чем: множество узлов, в которые вы записали данные, и множество узлов, из которых вы данные читаете, должны пересекаться. То есть среди читаемых узлов должен быть по крайней мере один узел с актуальным значением.
Зачастую значения w и r выбираются таким образом, чтобы составлять большинство (более чем n/2) узлов, поскольку это гарантирует, что система может позволить себе вплоть до n/2 сбойных узлов с соблюдением w + r > n. Но кворум не обязательно означает большинство — важен только аспект пересечения хотя бы в одном узле множества узлов, используемых операциями чтения и записи.
Можно также задать меньшие значения w и r так, что w + r ≤ n (то есть условие кворума не удовлетворяется). В этом случае информация об операциях чтения и записи будет по-прежнему отправляться на n узлов, но для успеха операции необходимо меньшее количество подтверждений успеха.
При меньших значениях w и r вероятность прочитать устаревшие значения возрастает, поскольку повышается вероятность того, что при чтении не будет охвачен узел с актуальным значением.
Положительный момент состоит в следующем: эта схема обещает более короткую задержку и более высокую доступность: при наличии сбоев сети и недоступности многих реплик шансы на дальшейшую обработку операций записи и чтения повышаются. Недоступной для записи или чтения база данных станет, только когда количество доступных реплик окажется ниже w и r соответственно.
Однако даже при w + r > n возможны граничные случаи, при которых будут возвращены устаревшие значения.
- При использовании нестрогого кворума w операций записи могут прийтись не на те узлы, что r операций чтения, поэтому гарантированного пересечения между множествами r узлов и w узлов нет.
- При конкурентном (параллельном) выполнении двух операций записи непонятно, какая из них произошла первой. В этом случае единственным «безопасным» решением будет слить воедино конкурентные операции. Если «победитель» выбирается на основе метки даты/времени («выигрывает последний»), существует вероятность потери информации об операциях записи вследствие рассинхронизации часов.
- Операция записи, выполняемая параллельно с чтением, может оказаться отраженной только в некоторых репликах. В этом случае неясно, вернет операция чтения новое или старое значение.
- Если операция записи прошла успешно в ряде реплик и неудачно в остальных, причем суммарно прошла успешно менее чем в w репликах, она не откатывается в последних. Это значит, что в случае уведомления о неудачной операции записи последующие операции чтения могут или вернуть соответствующее ей значение, или нет.
- В случае сбоя содержащего новое значение узла и его восстановления из содержащей старые данные реплики количество хранящих новое значение реплик может оказаться ниже w, нарушая тем самым условие кворума.
- Даже если все функционирует нормально, существуют граничные случаи с неудачным хронометражем
Следовательно, хотя кворум вроде бы гарантирует чтение последнего из записанных значений, на практике все не так просто. Dynamo-подобные базы данных в целом оптимизированы для сценариев использования, допускающих конечную согласованность. Параметры w и r предоставляют возможность влиять на вероятность чтения устаревших значений, но воспринимать их как абсолютные гарантии было бы неразумно.
Нестрогие кворумы и направленная передача
Базы данных с соответствующим образом заданным кворумом могут выдержать отказы отдельных узлов без необходимости восстановления. Могут они выдержать и замедление работы отдельных узлов, поскольку запросам не нужно ждать ответа от всех n узлов — достаточно, чтобы ответили w или r узлов. Эти характеристики делают БД с репликацией без ведущего узла подходящими для сценариев использования, требующих высокой доступности и низкого значения задержки, а также возможности выдержать происходящие иногда операции чтения устаревших данных.
Однако кворум (как описывалось выше) — не столь отказоустойчивый метод, как хотелось бы. Сетевые сбои с легкостью могут прервать связь клиента с большим количеством узлов базы данных. Хотя эти узлы продолжают функционировать и другие клиенты могут к ним подключиться, для отрезанного от них клиента они все равно что не работают.
В большом кластере (со значительно превышающим n числом узлов) вполне вероятно следующее: клиент сможет подключиться к некоторым узлам базы данных во время сбоя сети, но не к нужным ему, чтобы достичь кворума для конкретного значения.
Другой вариант известен под названием нестрогого кворума (sloppy quorum): для операций записи и чтения по-прежнему необходимо w и r подтверждений успешного выполнения, но при этом учитываются узлы, не входящие в число намеченных для значения n «родных» узлов. Здесь будет уместна такая аналогия: если вы потеряли ключи от квартиры, то можете постучать к соседям и попроситься переночевать у них на диване.
После исправления сбоя сети все операции записи, временно отправленные в какой-либо узел вместо недоступного, отправляются в соответствующие «родные» узлы. Это называется направленной передачей (hinted handoff). Аналогично, когда вы снова найдете ключи от квартиры, сосед вежливо попросит вас освободить диван и отправиться домой.
Нестрогие кворумы особенно полезны в деле повышения доступности для записи: база данных может принимать операции записи до тех пор, пока доступны любые w узлов. Однако это значит, что даже при w + r > n нельзя гарантировать чтение актуального значения для ключа, поскольку актуальное значение может быть временно записано на какие-то узлы вне множества n.
Следовательно, нестрогий кворум на самом деле вовсе не кворум в обычном смысле слова. Это просто гарантия сохраняемости данных, а именно сохранения данных в каких-то w узлах. Нет гарантий, что при чтении из r узлов они окажутся видны до тех пор, пока не будет завершена направленная передача.
Источники
Комментарии в Telegram-группе!