- Основы Распределенных Систем. Часть 1
- Основы Распределенных Систем. Часть 2
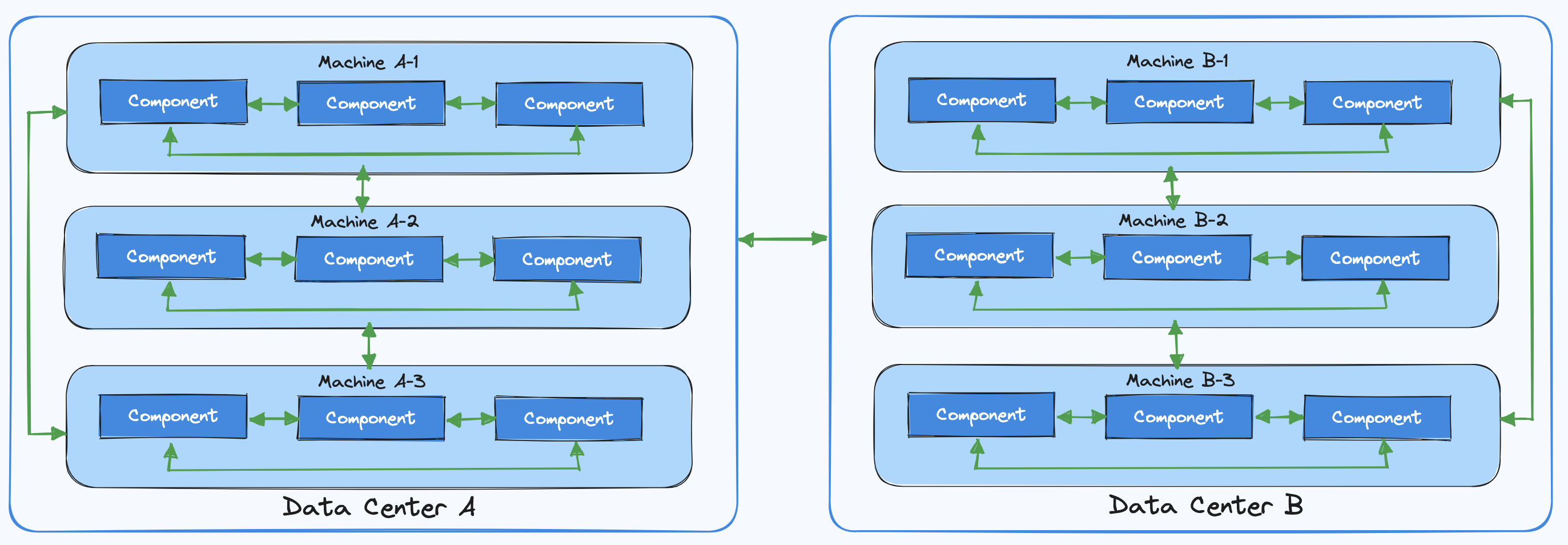
Распределенная система состоит из множества компонентов, возможно, находящихся на разных географических границах, которые взаимодействуют и координируют свои действия посредством передачи сообщений.
Для агента, находящегося вне этой системы, она представляется как единая целостная система:
Сейчас мы часто можем услышать о децентрализованных системах и спутать их с распределенными. Поэтому необходимо провести некоторые различия.
Децентрализованные системы - это распределенные системы, в которых ни один из компонентов не владеет принятием решений. Хотя каждый компонент владеет своей частью решения, ни один из них не обладает полной информацией. Следовательно, результат принятия решения зависит от некоего консенсуса между всеми компонентами.
Другой термин, очень тесно связанный с распределенными системами, - параллельные системы. Хотя оба термина относятся к увеличению вычислительных возможностей, способы их достижения различны. В параллельных вычислениях мы используем несколько процессоров на одной машине для одновременного выполнения нескольких задач, возможно, с общей памятью. Однако в распределенных вычислениях мы используем несколько автономных машин без общей памяти и обмениваемся сообщениями.
Преимущества распределенной системы
Хотя распределенные системы, безусловно, более сложны в проектировании и построении, они окупаются теми преимуществами, которые они дают.
- Масштабируемость(Scalability): Вертикальное масштабирование обычно упирается в аппаратные ограничениями. Однако теоретически мы можем достичь неограниченного горизонтального масштабирования с помощью относительно недорогих машин.
- Надежность(Reliability): Поскольку распределенная система состоит из нескольких машин, а данные реплицируются на нескольких узлах, она, как правило, более устойчива к выходу из строя какой-либо части системы. Таким образом, вся система продолжает функционировать, даже если ее производительность снижена.
- Производительность(Performance): Типичные приложения распределенных вычислений работают за счет разбиения рабочей нагрузки на более мелкие части, которые могут выполняться на нескольких машинах одновременно. Таким образом, это значительно повышает производительность многих сложных рабочих нагрузок, например, матричных умножений.
Проблемы в распределенной системе
- Согласованность(Consistency) против доступности(Availability): Поскольку распределенная система по определению обеспечивает устойчивость к разбиениям(partition tolerance), ей приходится выбирать между согласованностью и доступностью, как того требует теорема CAP.
- Распределение данных(Data Distribution): Данные или рабочая нагрузка в распределенной системе должны быть разбиты на части, чтобы отправить их на несколько узлов. Это приводит к необходимости разработки сложных алгоритмов для эффективного разбиения и последующего объединения данных.
- Координация(Coordination): Поскольку данные или рабочая нагрузка в распределенной системе также реплицируются на нескольких узлах для обеспечения отказоустойчивости, их координация становится очень сложной. Для согласования решений между узлами требуются сложные протоколы.
Часто в корпоративных приложениях требуется, чтобы в рамках одной транзакции выполнялось несколько операций. Например, нам может потребоваться выполнить несколько обновлений данных в рамках одной транзакции. Если при локальном размещении данных эта задача становится тривиальной, то при распределении данных по кластеру она становится достаточно сложной. Многие системы обеспечивают семантику транзакций в распределенной среде, используя такие сложные протоколы, как Paxos и Raft.
Архитектура распределенных систем
Архитектура распределенной системы зависит от конкретного случая использования и ожиданий от системы. Однако существуют общие закономерности.
По сути, это основные модели распределения, на которые опирается архитектура:
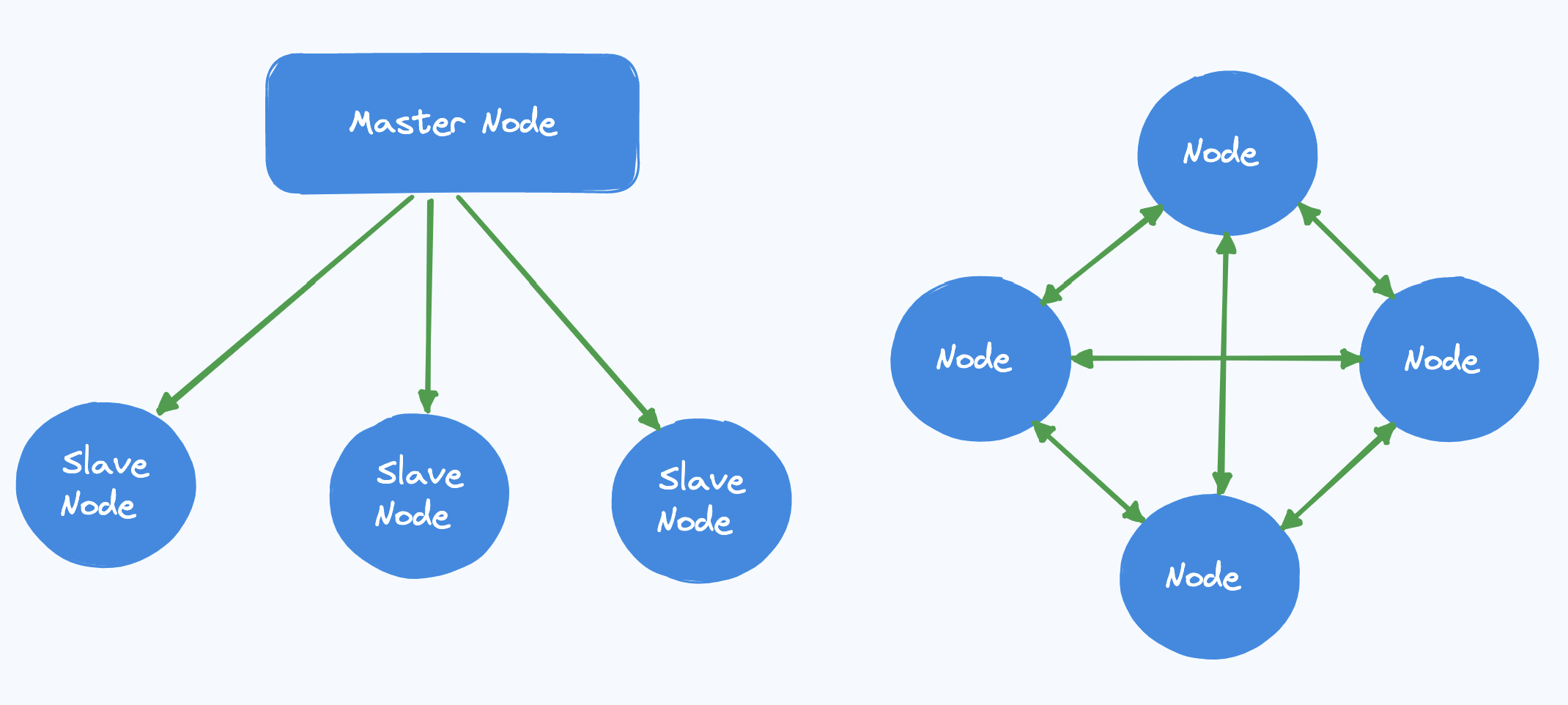
- Ведущий-ведомый(Master-slave): в этой модели один из узлов распределенной системы играет роль ведущего. Здесь ведущий узел обладает полной информацией о системе и контролирует принятие решений. Остальные узлы выступают в роли ведомых и выполняют задачи, поставленные перед ними ведущим узлом. Кроме того, для обеспечения отказоустойчивости ведущий узел может иметь избыточные резервные узлы.
- Одноранговая(Peer-to-peer): В этой модели распределенной системы среди узлов не выделяется один ведущий. Все узлы в равной степени разделяют обязанности ведущего. Таким образом, эта модель также известна как многомастерная(multi-master) или безмастерная(master-less). За счет увеличения сложности и коммуникационных накладных расходов эта модель обеспечивает лучшую отказоустойчивость системы.
Распределенные данные. Репликация
Хотя обе эти архитектуры имеют свои плюсы и минусы, не стоит выбирать только одну из них. Многие распределенные системы фактически создают архитектуру, сочетающую в себе элементы обеих моделей.
Одноранговая модель может обеспечивать распределение данных, а модель “ведущий-ведомый” - их репликацию в одной и той же архитектуре.
Категории распределенных систем
Причин для разработки распределенной системы может быть несколько. Например, в моделях машинного обучения нам необходимо выполнять такие вычисления, как умножение матриц в огромных масштабах. Такие вычисления невозможно выполнить на одной машине.
Аналогично, системы, работающие с огромными файлами, обрабатывающие и хранящие их на одной машине, могут быть просто невозможны или, по крайней мере, крайне неэффективны.
Таким образом, в зависимости от случая использования распределенные системы можно разделить на следующие категории.
- Хранилища данных(Datastores)
- Обмен сообщениями(Messaging)
- Вычисления(Computing)
- Регистрационные книги(Ledgers)
- Файловые системы(File-systems)
- Приложения(Applications)
Традиционно реляционные базы данных долгое время были выбором хранилища данных по умолчанию. Однако с ростом объема, разнообразия и скорости передачи данных в последнее время реляционные базы данных стали не оправдывать ожиданий. Именно здесь более полезными оказались базы данных NoSQL с их распределенной архитектурой.
Аналогичным образом, традиционные системы обмена сообщениями не могли оставаться защищенными от проблем, связанных с современными масштабами данных. Поэтому возникла потребность в распределенных системах обмена сообщениями, обеспечивающих производительность, масштабируемость и, возможно, долговечность. Сегодня в этой области существует несколько вариантов, обеспечивающих различные семантики, такие как публикация-подписка(publish-subscribe) и точка-точка(point-to-point).
Комментарии в Telegram-группе!