
- Репликация
- Репликация с несколькими ведущими узлами
- Конкурентные операции
- Секционирование
- Транзакции
- Слабые уровни изоляции
Заметки из книги Клеппмана “Высоконагруженные приложения”.
В этой части: Конкурентный доступ, время и относительность. Почему хорошо когда B причинно-следственно зависит от A. Зачем нужны векторы версий.
Обнаружение конкурентных операций записи
В Dynamo-подобных базах данных возможна конкурентная запись значения для одного ключа несколькими клиентами, что означает вероятность конфликтов даже при использовании строгих кворумов.
Проблема в том, что события могут поступать в разные узлы в разном порядке вследствие различных сетевых задержек и частичных отказов.
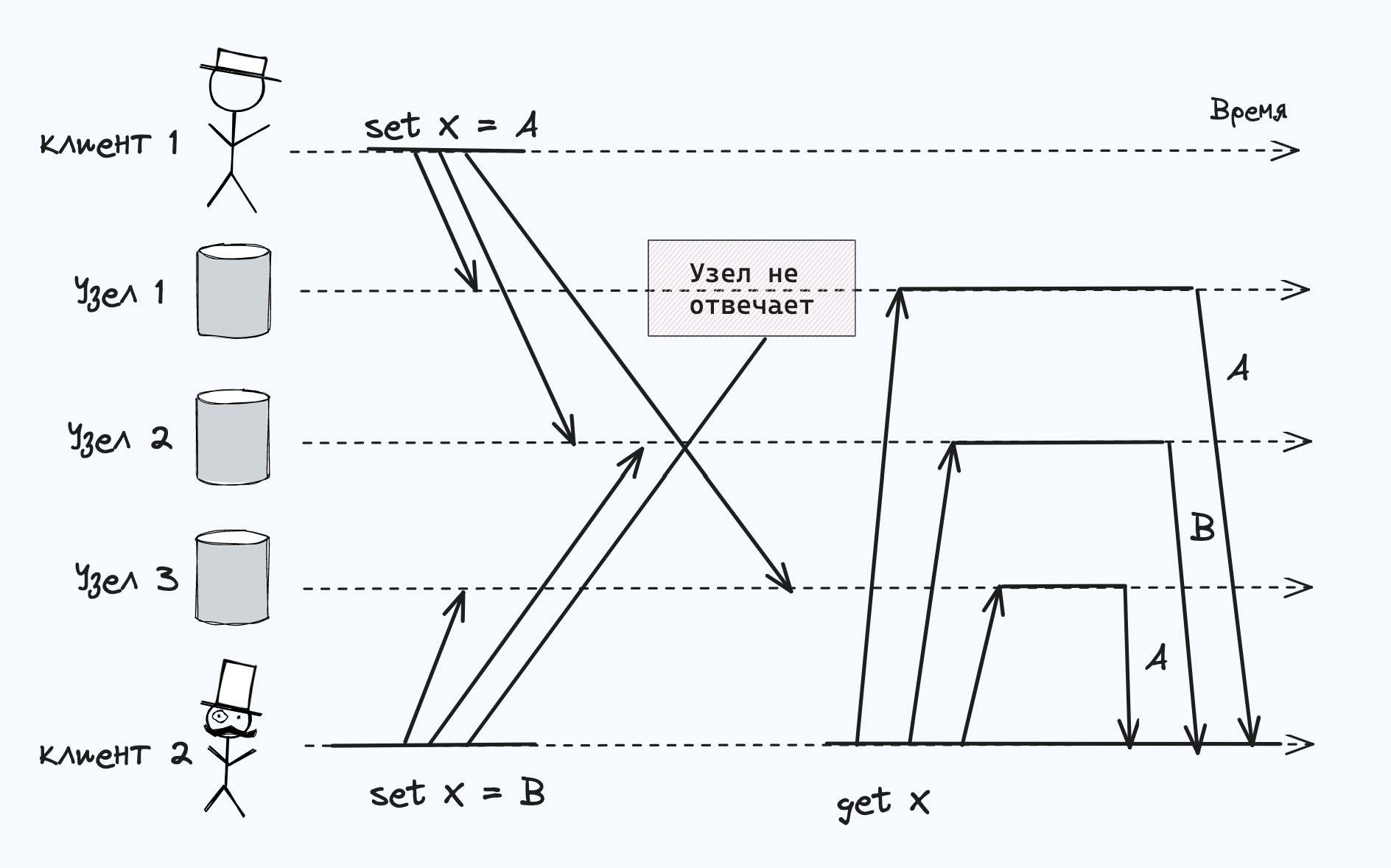
Если каждый из узлов будет просто переписывать значение для ключа при каждом получении запроса на запись от клиента, то узлы будут все время несогласованными, как видно из последнего запроса get на рис.: узел 2 считает, что итоговое значение X равно B, а остальные узлы — что A.
«Выигрывает последний» (отбраковка конкурентных операций записи)
Один из методов достижения в итоге конвергентности — провозгласить, что все реплики должны хранить только самое «свежее» значение, а более «старые» значения могут перезаписываться и игнорироваться. В этом случае все реплики будут стремиться к одному значению, если, конечно, у нас есть способ однозначного выяснения того, какая операция записи самая «свежая», и каждая операция записи в конце концов воспроизводится во всех репликах.
Фактически не имеет смысла говорить о «первенстве» какого-либо из них: говорится, что операции записи конкурентны, вследствие чего порядок их выполнения не определен.
Хотя операции записи не упорядочены сами по себе, мы можем навязать им произвольный порядок. Например, добавить в каждую операцию записи метку даты/времени, выбрать метку даты/времени с максимальным значением в качестве самой «свежей» и отбросить все операции записи с более ранними метками. Такой метод разрешения конфликтов, называемый «выигрывает последний» (last write wins, LWW), — единственный алгоритм разрешения конфликтов, поддерживаемый СУБД Cassandra, и дополнительная возможность в Riak.
LWW позволяет достичь в итоге конвергентности, но за счет сохраняемости данных: в случае нескольких конкурентных операций записи для одного и того же ключа, для которых клиент мог даже получить подтверждение их успешного выполнения (поскольку они записывались на w реплик), только одна из операций записи будет учтена, а остальные — незаметно проигнорированы.
Существует ряд ситуаций, например кэширование, при которых, возможно, потеря части операций записи допустима. Если же потеря данных неприемлема, то LWW — не лучший способ разрешения конфликтов.
Единственный безопасный способ использования базы данных с LWW — позаботиться, чтобы ключ записывался лишь один раз, после чего рассматривался как неизменяемый, благодаря чему можно избежать любых конкурентных обновлений одного ключа. Например, рекомендуемый способ применения Cassandra — задействовать в качестве ключа UUID, присваивая, таким образом, каждой операции записи уникальный ключ.
Связь типа “происходит до” и конкурентный доступ
Как определить, конкурентны ли две операции?
- две операции записи не конкурентны: вставка, выполненная клиентом A, происходит до (happens-befor) приращения, выполненного клиентом B, поскольку увеличиваемое клиентом B значение — как раз то, которое вставил клиент A.
Другими словами, выполняемая клиентом B операция основана на операции, выполняемой клиентом A, поэтому операция клиента B должна выполняться позднее. Можно также сказать, что B причинно-следственно зависит от A. - две операции записи конкурентны: в момент начала операции ни один из клиентов не знает, что другой тоже выполняет операцию над тем же ключом. Следовательно, причинно-следственной связи между этими операциями нет.
Говорят, что операция A происходит до другой операции B, если B известно про A или B зависит от A либо основана на A каким-либо образом. Совершение одной операции до другой — ключ к формализации понятия конкурентности. Фактически мы можем просто сказать: две операции конкурентны, если ни одна из них не происходит до другой (то есть ни одна не знает про другую).
Следовательно, для двух операций A и B есть три возможности: или A происходит до B, или B происходит до A, или A и B происходят конкурентно.
Конкурентный доступ, время и относительность
Может показаться, что две операции должны называться конкурентными тогда, когда происходят одновременно, но на деле неважно, пересекаются ли они во времени. Вследствие проблем с часами в распределенных системах реально довольно сложно определить, происходят ли два события фактически в одно и то же время.
Чтобы определить, что такое конкурентный доступ, точное время неважно: мы просто будем называть две операции конкурентными, если ни одна из них не знает о другой, независимо от физического времени их выполнения. Иногда этот принцип связывается со специальной теорией относительности в физике, в которой излагается идея о невозможности перемещения информации со скоростью, превышающей скорость света. В результате два происходящих на некоем расстоянии события никак не могут влиять друг на друга, если разделяющий их промежуток времени меньше, чем время, которое потребовалось бы лучу света для прохождения соответствующего расстояния.
Обнаружение связей типа “происходит до”
Взглянем на алгоритм, который определяет, являются ли две операции конкурентными, или одна происходит до другой.
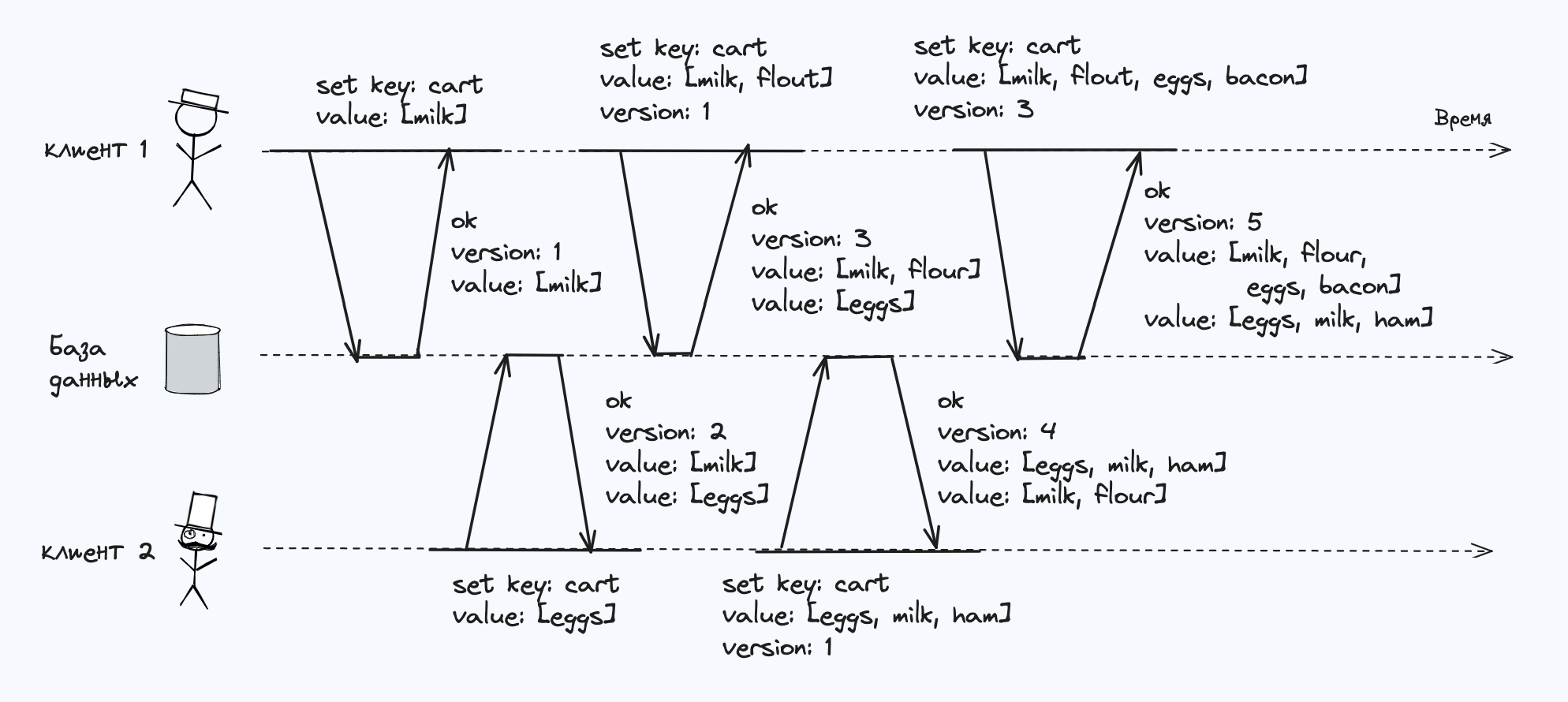
На рис. показаны два клиента, конкурентно добавляющие товары в одну корзину заказов
- Клиент 1 добавляет в корзину заказов milk. Это первая операция записи для данного ключа, так что сервер успешно сохраняет данные и присваивает ей номер версии 1. Сервер также возвращает текущее значение клиенту вместе с номером версии.
- Клиент 2 добавляет в корзину заказов eggs, не зная, что клиент 1 конкурентно добавил milk
- Клиент 1, не замечая операции записи клиента 2, собирается добавить в корзину flour, считая, что после этого содержимое корзины заказов будет [milk, flour]. Он отправляет данное значение на сервер вместе с номером версии 1, присвоенной ему ранее. Сервер понимает по номеру версии, что запись [milk, flour] заменяет предыдущее значение [milk], но конкурентна с [eggs]. Следовательно, сервер присваивает [milk, flour] версию 3, замещая значение [milk] версии 1 и сохраняя значение [eggs] версии 2, и возвращает оба оставшихся значения клиенту.
- Тем временем клиент 2 хочет добавить в корзину ham, не подозревая, что клиент 1 только что добавил flour. Клиент 2 получил в последнем ответе сервера два значения — [milk] и [eggs], вследствие чего сливает эти значения воедино и добавляет ham для формирования нового значения — [eggs, milk, ham]. Сервер обнаруживает, что версия 2 замещает [eggs], но конкурентна с [milk, flour], поэтому остаются два значения [milk, flour] с версией 3 и [eggs, milk, ham] с версией 4.
- Наконец, клиент 1 хочет добавить в корзину bacon. Ранее он уже добавил [milk, flour] и [eggs] с сервера с версией 3, так что он объединяет их, добавляет bacon и отправляет итоговое значение [milk, flour, eggs, bacon] серверу с номером версии 3. Это значение замещает [milk, flour] (обратите внимание: [eggs] уже заменены на предыдущем шаге), но конкурентно с [eggs, milk, ham], вследствие чего сервер сохраняет эти два конкурентных значения.
Поток данных между операциями проиллюстрирован графически на рис. ниже. Стрелки указывают, какие операции произошли до других операций в том смысле, что более поздняя операция знает о более ранней или зависит от нее. В этом примере клиенты никогда не идут в ногу с данными на сервере, поскольку всякий раз конкурентно происходит еще одна операция. Но устаревшие версии значений постоянно перезаписываются, и ни одна операция записи не оказывается потерянной.
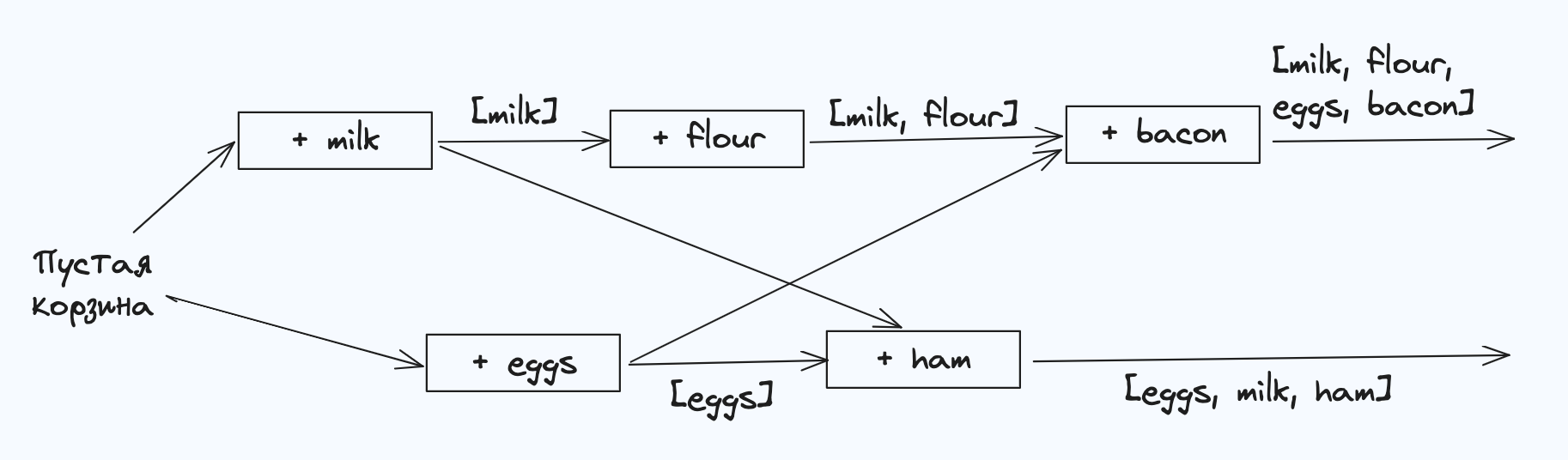
Обратите внимание: сервер может определить, являются ли две операции конку- рентными, по номерам версий — ему не требуется интерпретировать сами значения (так что те могут представлять собой произвольные структуры данных). Алгоритм работает следующим образом.
- Сервер хранит номера версий для всех ключей, увеличивая номер версии всякий раз при выполнении записи значения для этого ключа, и сохраняет новый номер версии вместе с записанным значением.
- При чтении ключа клиентом сервер возвращает все неперезаписанные значения, а также последний номер версии. Клиент должен прочитать ключ перед операцией записи.
- Клиент, записывая значение для ключа, должен включить номер версии из предыдущей операции чтения, а также объединить все полученные при предыдущей операции чтения значения. (Полученный в результате операции записи ответ может быть таким же, как и для чтения, с возвратом всех текущих значений, что позволяет соединять несколько операций записи последовательно, подобно примеру с корзиной заказов.)
- Сервер, получив информацию об операции записи с конкретным номером версии, может перезаписать все значения с этим или более низким номером версии (так как знает, что они все слиты воедино в новом значении), но должен сохранить все значения с более высоким номером версии (поскольку эти значения конкурентны данной входящей операции записи).
Номер версии из предыдущей операции, включаемый в операцию записи, обеспечивает информацию о том, на каком предыдущем состоянии основана эта операция записи. Операция записи, в которую не включен номер версии, будет конкурентна всем остальным операциям записи, так что не будет перезаписывать никакие данные, ее данные просто будут возвращены в качестве одного из значений при последующих операциях чтения.
Слияние конкурентно записываемых значений
Вышеприведенный алгоритм гарантирует, что данные не будут незаметно отбрасываться, но при этом клиентам приходится выполнять дополнительную работу: освобождать занимаемые ресурсы после конкурентного совершения нескольких операций путем объединения конкурентно записываемых значений. В Riak такие конкурентные значения называются родственными значениями (siblings).
Слияние родственных значений представляет собой, по сути, аналог обсуждавшейся выше задачи разрешения конфликтов при репликации с несколькими ведущими узлами. Простейший подход: выбрать одно из значений на основе номера версии или метки даты/времени («выигрывает последний»), но это означает потерю данных. Поэтому необходимо сделать в коде приложения нечто более изощренное.
В примере с корзинами заказов разумным подходом было бы просто объединить значения. Два итоговых родственных значения — [milk, flour, eggs, bacon] и [eggs, milk, ham]; обратите внимание: milk и eggs встречаются в обоих, хотя каждое из них записывалось однократно. Объединенное значение может выглядеть примерно следующим образом: [milk, flour, eggs, bacon, ham], без дубликатов.
Однако если вы хотите, чтобы люди могли и удалять товары из корзин заказов, а не только добавлять, то результат объединения родственных значений может оказаться не тем, который вам нужен: при объединении двух родственных корзин с удалением товара только из одной удаленный товар снова появится в объединении. Чтобы избежать такой ситуации, нельзя просто удалять товар из базы данных при удалении его из корзины заказов, вместо этого система должна оставить в базе маркер с соответствующим номером версии в качестве указания на то, что товар был удален при слиянии родственных значений. Подобный маркер называется отметкой об удалении (tombstone).
Векторы версий
В примере выше используется только одна реплика. Как же изменится алгоритм при наличии нескольких реплик, но без ведущего узла?
В примере применяется один номер версии для отражения зависимостей между операциями, но его недостаточно при наличии нескольких реплик, конкурентно принимающих информацию об операциях записи. Вместо этого необходимо воспользоваться не только номером версии по ключам, но и номером версии по репликам. У каждой реплики есть свой собственный номер версии, который она увеличивает при выполнении каждой операции записи, отслеживая между тем попадающие к ней номера версий от каждой из других реплик. Исходя из данной информации одни
Набор номеров версий всех реплик называется вектором версий (version vector). Используется несколько разновидностей этого понятия, но самая интересная из них, вероятно, точечный вектор версий (dotted version vector), применяемый в Riak.
Bекторы версий отправляются клиентам от реплик базы данных при чтении значений и должны отправляться обратно в БД при последующей записи значения (Riak кодирует вектор версий в виде строки, называемой причинно-следственным контекстом (causal context)). Вектор версий дает базе возможность различать операции перезаписи и конкурентные операции записи.
Кроме того, подобно примеру с одной репликой, приложению может понадобиться объединить родственные значения. Структура вектора версий гарантирует безопасность чтения из одной реплики с последующей записью в другую. Это способно привести к созданию родственных значений, но данные не теряются, если, конечно, родственные значения были объединены правильно.
Векторы версий иногда называют векторными часами (vector clock), хотя это не совсем одно и то же. Различие между ними едва уловимо. Если в двух словах, то при сравнении состояний реплик следует использовать именно векторы версий.
Резюме по репликациям
Репликация может служить нескольким целям:
- Высокая доступность. Сохранение работоспособности системы в целом даже в случае отказа одной из машин (или нескольких машин, или даже целого ЦОДа).
- Работа в офлайн-режиме. Возможность продолжения работы приложения в случае прерывания соединения с сетью.
- Задержка. Данные размещаются географически близко к пользователям, чтобы те могли работать с ними быстрее.
- Масштабирование. Возможность обрабатывать большие объемы операций чтения, чем способна обработать одна машина, с помощью выполнения операций чтения на репликах.
Три основных метода репликации:
- Репликация с одним ведущим узлом. Клиенты отправляют информацию обо всех операциях записи одному узлу (ведущему), который отправляет поток событий изменения данных другим репликам (ведомым узлам). Операции чтения могут выполняться в любой реплике, но прочитанные из ведомых узлов данные могут оказаться устаревшими.
- Репликация с несколькими ведущими узлами. Клиенты отправляют информацию о каждой из операций записи одному из нескольких ведущих узлов, могущих эту информацию принимать. Ведущие могут отправлять поток событий изменения данных друг другу и любым ведомым.
- Репликация без ведущего узла. Клиенты отправляют информацию о каждой из операций записи одному из нескольких узлов и читают из нескольких узлов параллельно, чтобы обнаружить узлы с устаревшими данными и внести поправки.
У каждого из этих методов есть свои достоинства и недостатки. Репликация с одним ведущим узлом широко распространена в силу своей простоты и отсутствия надобности в разрешении конфликтов. Методы репликации с несколькими ведущими узлами и без ведущего узла, возможно, более устойчивы к отказам узлов, разрывам сети и резким скачкам времени задержки за счет усложнения и обеспечения лишь очень слабых гарантий согласованности.
Моделей согласованности, полезных при решении вопроса о требуемом поведении приложения в случае задержки репликации:
- Согласованность типа «чтение после записи». Пользователи должны всегда видеть данные, которые они сами отправили в БД.
- Монотонное чтение. После того как пользователь увидел данные по состоянию на какой-либо момент времени, он не должен позднее увидеть те же данные по состоянию на более ранний момент времени.
- Согласованное префиксное чтение. Пользователи должны видеть данные в состоянии, не нарушающем причинно-следственных связей: например, видеть вопрос и ответ на него в правильном порядке.
Источники
Комментарии в Telegram-группе!